Introduction
Overview
Teaching: 10 min
Exercises: 0 minQuestions
Why use version control?
Objectives
Understand the benefits of an automated version control system.
Understand the difference between Git and GitHub.
What is a version control system?
Version control is a piece of software which allows you to record and preserve the history of changes made to directories and files. If you mess things up, you can retrieve an earlier version of your project.
Why use a version control system?
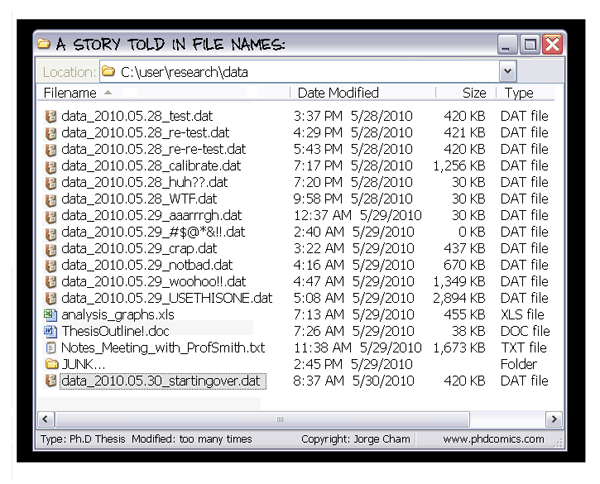
](../fig/phd101212s.png)
The comic above illustrates some of pitfalls of working without version control. Some of the benefits are given below:
Storing versions (properly)
Saving files after you have made changes should be an automatic habit. However if you want to have different versions of your code, you will need to save the new version somewhere else or with a different name.
- Do you just save the file(s) you changed, or all the files in the project?
- How do you name these different versions? It is very easy to lose track of what is what.
- How do you know what is different between each version?
Without a VCS you will probably end up with lots of nearly-identical (but critically different) copies of the same file, which is confusing and wastes hard drive space. Your project will probably start to look like this:
A VCS treats your files as one project, so you only have one current version on your disk (the working copy) - all the other variants and previous versions are saved in the VCS repository. A VCS starts with a base version of your project and only saves the changes you make along the way, so it is much more space efficient too.
Add changes sequentially

Save different versions

Merge different versions

Restoring previous versions
The ability to restore previous versions of a file (or all the files in your project) greatly reduces the scope for screw ups. If you make changes which you later want to abandon (e.g. the wording of your conclusion section was better before you started making changes, your code changes end up breaking things which previously worked and you can’t figure out why etc), you can just undo them by restoring a previous version.
Understanding what happened
Each time you save a new version of your project, VCS requires you to give a description of why you made the changes. This helps identify which version is which.
Backup
For distributed version control like Git, each person working on the project has a complete copy of the project’s history (i.e. the repository) on their hard drive. This acts as a backup for the server hosting the remote repository.
Collaboration
Without VCS, you are probably using a shared drive and taking turns to edit files, or emailing files back and forth. This makes it really easy to overwrite or abandon someone else’s changes because you have to manually incorporate the other person’s changes into your version and vice versa.
With VCS, everyone is able to work on any file at any time without affecting anyone else. The VCS will then help you merge all the changes into a common version. It is also always clear where the most recent version is kept (in the repository).
Example scenario
Think about the following situation:
You are working on a handful of MATLAB files. You make a few changes, and then you want to try something you’re not quite confident about yet, so you save a copy in another folder just in case.
Then you want to try out the program with more data on a bigger machine, and you make a few changes there to get it working properly. Then you try out something else in the copy on your laptop.
Now you have three or four copies, all slightly different, and you have some results generated from all of them, and you include some of it in a paper.
Then someone asks for the same results based on a new data file. You have to go off and remind yourself which version you used, find out whether you still have it at all or whether you’ve changed it again since, check whether it really has the vital changes you thought you’d included but that might have been only on that other machine, and so on.
You should easily be able to see the benefits of VCS in the situation above.
What files can I track using version control?
VCS is typically used for software source code, but it can be used for any kind of text file:
- Configuration files
- Parameter sets
- Data files
- User documentation, manuals, and journal papers, whether they be plain-text, LaTeX, XML, md etc
- Have a look at some of the projects on GitHub
Why should I avoid tracking binary files with version control?
It is possible to add binary files to a Git repository, but this is usually a bad idea:
- diffs between versions become meaningless
- binary files are often large, and thus slow down your repository
- changes to binary files often required a whole new copy to be saved, so your repository can quickly grow in size
Strategies for dealing with large binary files are discussed here.
Git vs GitHub
For this session, we’ll be using Git, a popular distributed version control system and GitHub, a web-based service providing remote repositories. Distributed means that each user has a complete copy of the repository on their computer and can commit changes offline. If you have used a centralized version control system before e.g. Subversion, this will be one of the major differences to how you are used to working. See here for a more detailed comparison of Git and Subversion.
Key Points
Git is a version control tool; one of many.
GitHub is a repository hosting service; one of many.
Use version control to store versions neatly, restore previous versions, understand what happened (and why), and always know which is the current version.
Tracking changes with a local repository
Overview
Teaching: 35 min
Exercises: 0 minQuestions
How do I get started with Git?
Where does Git store information?
Objectives
Know how to set up a new Git repository.
Understand how to start tracking files.
Be able to commit changes to your repository.
Version control is centred round the notion of a repository which holds your directories and files. We’ll start by looking at a local repository. The local repository is set up in a directory in your local filesystem (local machine). For this we will use the command line interface.
Why use the command line?
There are lots of graphical user interfaces (GUIs) for using Git: both stand-alone and integrated into IDEs (e.g. MATLAB, Rstudio). We are deliberately not using a GUI for this course because:
- you will have a better understanding of how the git comands work (some functionality is often missing and/or unclear in GUIs)
- you will be able to use Git on any computer (e.g. remotely accessing HPC systems, which generally only have Linux command line access)
- you will be able to use any GUI, rather than just the one you have learned
Setting up Git
Git is already installed on the training machines, whether you’re using Windows or Linux. Instructions for setting up Git on your own machine are given under setup.
Tell Git who we are
As part of the information about changes made to files Git records who made those changes. In teamwork this information is often crucial (do you want to know who rewrote your ‘Conclusions’ section?). So, we need to tell Git about who we are (note that you need to enclose your name in quote marks):
$ git config --global user.name "Your Name" # Put your quote marks around your name
$ git config --global user.email yourname@yourplace.org
Set a default editor
When working with Git we will often need to provide some short but useful information. In order to enter this information we need an editor. We’ll now tell Git which editor we want to be the default one (i.e. Git will always bring it up whenever it wants us to provide some information).
You can choose any editor available on your system. Choose one of the three options below
$ git config --global core.editor gedit # Linux users only
$ git config --global core.editor notepad # Windows users should use notepad
$ git config --global core.editor 'open -W -n' # Mac users should use TextEdit
Git’s global configuration
We can now preview (and edit, if necessary) Git’s global configuration (such as
our name and the default editor which we just set up). If we look in our home
directory, we’ll see a .gitconfig file,
$ cat ~/.gitconfig
[user]
name = Your Name
email = yourname@yourplace.org
[core]
editor = gedit
These global configuration settings will apply to any new Git repository
you create on your computer.
i.e. the --global commands above are only required once per computer.
Create a new repository with Git
We will be working with a simple example in this tutorial. It will be a paper that we will first start writing as a single author and then work on it further with one of our colleagues.
First, let’s create a directory within your home directory:
$ cd # Switch to your home directory.
$ pwd # Print working directory (output should be /home/<username>)
$ mkdir paper
$ cd paper
Now, we need to set up this directory up to be a Git repository (or “initiate the repository”):
$ git init
Initialized empty Git repository in /home/user/paper/.git/
The directory “paper” is now our working directory.
If we look in this directory, we’ll find a .git directory:
$ ls .git
branches config description HEAD hooks info objects refs
The .git directory contains Git’s configuration files. Be careful not to
accidentally delete this directory!
Tracking files with a git repository
Now, we’ll create a file. Let’s say we’re going to write a journal paper, so we will start by adding the author names and a title, then save the file.
$ gedit paper.md # Windows and Mac users see below for text editors available on your system
# Add author names and paper title
Text editors on your OS
This course is written for Linux, where
geditshould be available. If you are using Windows, usenotepadinstead:notepad paper.mdSimilarly, if you are using macOS, use TextEdit:
open -e paper.md
Accessing files from the command line
In this lesson we create and modify text files using a command line interface (e.g. terminal, Git Bash etc), mainly for convenience. These are normal files which are also accessible from the file browser (e.g. Windows explorer), and by other programs.
git status allows us to find out about the current status
of files in the repository. So we can run,
$ git status
On branch master
Initial commit
Untracked files:
(use "git add <file>..." to include in what will be committed)
paper.md
nothing added to commit but untracked files present (use "git add" to track)
Information about what Git knows about the directory is displayed. We are on
the master branch, which is the default branch in a Git respository
(one way to think of branches is like parallel versions of the project - more
on branches later).
For now, the important bit of information is that our file is listed as Untracked which means it is in our working directory but Git is not tracking it - that is, any changes made to this file will not be recorded by Git.
Add files to a Git repository
To tell Git about the file, we will use the git add command:
$ git add paper.md
$ git status
On branch master
Initial commit
Changes to be committed:
(use "git rm --cached <file>..." to unstage)
new file: paper.md
Now our file is listed underneath where it says Changes to be committed.
git add is used for two purposes. Firstly, to tell Git that a given file
should be tracked. Secondly, to put the file into the Git staging area
which is also known as the index or the cache.
The staging area can be viewed as a “loading dock”, a place to hold files we have added, or changed, until we are ready to tell Git to record those changes in the repository.

Commit changes
In order to tell Git to record our change, our new file, into the repository, we need to commit it:
$ git commit
# Type a commit message: "Add title and authors"
# Save the commit message and close your text editor (gedit, notepad etc.)
Our default editor will now pop up. Why? Well, Git can automatically figure out that directories and files are committed, and by whom (thanks to the information we provided before) and even, what changes were made, but it cannot figure out why. So we need to provide this in a commit message.
If we save our commit message and exit the editor, Git will now commit our file.
[master (root-commit) 21cfbde]
1 file changed, 2 insertions(+) Add title and authors
create mode 100644 paper.md
This output shows the number of files changed and the number of lines inserted or deleted across all those files. Here, we have changed (by adding) 1 file and inserted 2 lines.
Now, if we look at its status,
$ git status
On branch master
nothing to commit, working directory clean
our file is now in the repository.
The output from the git status command means that we have a clean directory
i.e. no tracked but modified files.
Now we will work a bit further on our paper.md file by starting the introduction section.
$ gedit paper.md
# Write introduction section
If we now run,
$ git status
we see changes not staged for commit section and our file is marked as modified:
On branch master
Changes not staged for commit:
(use "git add <file>..." to update what will be committed)
(use "git checkout -- <file>..." to discard changes in working directory)
modified: paper.md
no changes added to commit (use "git add" and/or "git commit -a")
This means that a file Git knows about has been modified by us but has not yet been committed. So we can add it to the staging area and then commit the changes:
$ git add paper.md
$ git commit # "Write introduction"
Note that in this case we used git add to put paper.md to the staging
area. Git already knows this file should be tracked but doesn’t know if we want
to commit the changes we made to the file in the repository and hence we have
to add the file to the staging area.
It can sometimes be quicker to provide our commit messages at the command-line
by doing git commit -m "Write introduction section".
In our introduction, we should cite a paper describing the main instrument used.
$ gedit paper.md # Cite instrument paper in introduction
Let’s also create a file refs.txt to hold our references:
$ gedit refs.txt # Add the reference
Now we need to record our work in the repository so we need to make a commit. First we tell Git to track the references.
$ git add refs.txt # Track the refs.txt file
$ git status # Verify that refs.txt is now tracked
The file refs.txt is now tracked. We also have to add
paper.md to the staging area. But there is a shortcut. We can use
commit -a. This option means “commit all files that are tracked and
that have been modified”.
$ git commit -am "Reference J Bloggs and add references file" # Add and commit all tracked files
and Git will add, then commit, both the directory and the file.
In order to add all tracked files to the staging area, use git commit -a
(which may be very useful if you edit e.g. 10 files and now you want to commit all of them).

Key Points
git initinitializes a new repository
git statusshows the status of a repositoryFiles can be stored in a project’s
working directory(which users see), thestaging area(where the next commit is being built up) and thelocal repository(where commits are permanently recorded)
git addputs files in the staging area
git commitsaves the staged content as a new commit in the local repositoryAlways write a log message when committing changes
Looking at history and differences
Overview
Teaching: 30 min
Exercises: 15 (inc 10 for break) minQuestions
How do I get started with Git?
Where does Git store information?
Objectives
Be able to view history of changes to a repository
Be able to view differences between commits
Understand how and when to use tags to label commits
Looking at differences
We should reference some previous work in the introduction section. Make the required changes, save both files but do not commit the changes yet. We can review the changes that we made using:
$ gedit paper.md # Cite previous studies in introduction
$ gedit refs.txt # Add the reference to the database
$ git diff # View changes
This shows the difference between the latest copy in the repository and the unstaged changes we have made.
-means a line was deleted.+means a line was added.- Note that a line that has been edited is shown as a removal of the old line and an addition of the updated line.
Looking at differences between commits is one of the most common activities.
The git diff command itself has a number of useful
options.
There is also a range of GUI-based tools for looking at differences and editing files. For example:
- Diffmerge (Free, cross-platform)
- WinMerge - open source tool available for Windows;
- GitHub Compare view
Git can be configured to use graphical diff tools, and this is functionality
is accessed using git difftool in place of git diff.
Configuring a visual diff tool is covered on the
hints and tips page.
The choice of GUI for viewing differences depends on the context in which you
are working and your own preferences related to choosing tools and
technologies.
Now commit the change we made by adding the second reference:
$ git add paper.md refs.txt
$ git commit # "Cite previous work in introduction"
Looking at our history
To see the history of changes that we made to our repository (the most recent changes will be displayed at the top):
$ git log
commit 8bf67f3862828ec51b3fdad00c5805de934563aa
Author: Your Name <your.name@manchester.ac.uk>
Date: Mon Jun 26 10:22:39 2017 +0100
Cite PCASP paper
commit 4dd7f5c948fdc11814041927e2c419283f5fe84c
Author: Your Name <your.name@manchester.ac.uk>
Date: Mon Jun 26 10:21:48 2017 +0100
Write introduction
commit c38d2243df9ad41eec57678841d462af93a2d4a5
Author: Your Name <your.name@manchester.ac.uk>
Date: Mon Jun 26 10:14:30 2017 +0100
Add author and title
The output shows (on separate lines):
- the commit identifier (also called revision number) which uniquely identifies the changes made in this commit
- author
- date
- your commit message
Git automatically assigns an identifier (e.g. 4dd7f5) to each commit
made to the repository
— we refer to this as COMMITID in the code blocks below.
In order to see the changes made between any earlier commit and our
current version, we can use git diff followed by the commit identifier of the
earlier commit:
$ git diff COMMITID # View differences between current version and COMMITID
And, to see changes between two commits:
$ git diff OLDER_COMMITID NEWER_COMMITID
Using our commit identifiers we can set our working directory to contain the state of the repository as it was at any commit. So, let’s go back to the very first commit we made,
$ git log
$ git checkout INITIAL_COMMITID
We will get something like this:
Note: checking out '21cfbdec'.
You are in 'detached HEAD' state. You can look around, make experimental
changes and commit them, and you can discard any commits you make in this
state without impacting any branches by performing another checkout.
If you want to create a new branch to retain commits you create, you may
do so (now or later) by using -b with the checkout command again. Example:
git checkout -b new_branch_name
HEAD is now at 21cfbde... Add title and authors
This strange concept of the ‘detached HEAD’ is covered in the next section … just bear with me for now!
If we look at paper.md we’ll see it’s our very first version. And if we
look at our directory,
$ ls
paper.md
then we see that our refs.txt file is gone. But, rest easy, while it’s
gone from our working directory, it’s still in our repository. We can jump back
to the latest commit by doing:
$ git checkout master
And refs.txt will be there once more,
$ ls
paper.md refs.txt
So we can get any version of our files from any point in time. In other words, we can set up our working directory back to any stage it was when we made a commit.
The HEAD and master pointers
HEAD is a reference, or pointer, which points to the branch at the commit where
you currently are.
We said previously that master is the default branch. But master is
actually a pointer - that points to the tip of the master branch (the sequence
of commits that is created by default by Git). You may think of master as two
things:
- a pointer
- the default branch.
Before we checked out one of the past commits, the HEAD pointer was pointing to
master i.e. the most recent commit of the master branch.
After checking out one of the past commits, HEAD was pointing to that commit i.e.
not pointing to master any more.
That is what Git means by a ‘detached HEAD’ state and advises us that if we want to make a commit
now, we should create a new branch to retain these commits.

If we created a new commit without first creating a new branch, i.e. working from the ‘detached HEAD’ these commits would not overwrite any of our existing work, but they would not belong to any branch. In order to save this work, we would need to checkout a new branch. To discard any changes we make from the detached HEAD state, we can just checkout master again.
Visualising your own repository as a graph
If we use git log with a couple of options, we can display the history as a graph,
and decorate those commits corresponding to Git references (e.g. HEAD, master):
$ git log --graph --decorate --oneline
* 6a48241 (HEAD, master) Cite previous work in introduction
* ed26351 Cite PCASP paper
* 7446b1d Write introduction
* 4f572d5 Add title and author
Notice how HEAD and master point to the same commit.
Now checkout a previous commit again, and look at the graph again.
We can display, this time specifying that we want to look at --all the history,
rather than just up to the current commit.
$ git checkout HEAD~ # This syntax refers to the commit before HEAD
$ git log --graph --decorate --oneline --all
* 6a48241 (master) Reference second paper in introduction
* ed26351 (HEAD) Reference Allen et al in introduction
* 7446b1d Write introduction
* 4f572d5 Add title and authors
Notice how HEAD no longer points to the same commit as master.
Let’s return to the current version of the project by checking out master again.
$ git checkout master
Using tags as nicknames for commit identifiers
Commit identifiers are long and cryptic. Git allows us to create tags, which act as easy-to-remember nicknames for commit identifiers.
For example,
$ git tag PAPER_STUB
We can list tags by doing:
$ git tag
Let’s explain to the reader why this research is important:
$ gedit paper.md # Give context for research
$ git add paper.md
$ git commit -m "Explain motivation for research" paper.md
We can checkout our previous version using our tag instead of a commit identifier.
$ git checkout PAPER_STUB
And return to the latest checkout,
$ git checkout master
Top tip: tag significant events
When do you tag? Well, whenever you might want to get back to the exact version you’ve been working on. For a paper, this might be a version that has been submitted to an internal review, or has been submitted to a conference. For code this might be when it’s been submitted to review, or has been released.
Where to create a Git repository?
Avoid creating a Git repository within another Git repository. Nesting repositories in this way causes the ‘outer’ repository to track the contents of the ‘inner’ repository - things will get confusing!
Exercise: “bio” Repository
- Create a new Git repository on your computer called “bio”
- Be sure not to create your new repo within the ‘paper’ repo (see above)
- Write a three-line biography for yourself in a file called me.txt
- Commit your changes
- Modify one line, add a fourth line, then save the file
- Display the differences between the updated file and the original
You may wish to use the faded example below as a guide
cd .. # Navigate out of the paper directory # Avoid creating a repo within a repo - confusion will arise! mkdir ___ # Create a new directory called 'bio' cd ___ # Navigate into the new directory git ____ # Initialise a new repository _____ me.txt # Create a file and write your biography git ___ me.txt # Add your biography file to the staging area git ______ # Commit your staged changes _____ me.txt # Edit your file git ____ me.txt # Display differences between your modified file and the last committed versionSolution
cd .. # Navigate out of the paper directory # Avoid creating a repo within a repo - confusion will arise! mkdir bio # Create a new directory cd bio # Navigate into the new directory git init # Initialise a new repository gedit me.txt # Create a file and write your biography git add me.txt # Add your biography file to the staging area git commit # Commit your staged changes gedit me.txt # Edit your file git diff me.txt # Display differences between your modified file and the last committed version
Key Points
git logshows the commit history
git diffdisplays differences between commits
git checkoutrecovers old versions of files
HEADpoints to the commit you have checked out
masterpoints to the tip of themasterbranch
Commit advice
Overview
Teaching: 10 min
Exercises: 0 minQuestions
How, what, and when to commit?
What makes a good commit message?
Objectives
Understand what makes a good commit message
Know which types of files not to commit
Know when to commit changes
How to write a good commit message
Commit messages should explain why you have made your changes. They should mean something to others who may read them — including your future self in 6 months from now. As such you should be able to understand why something happened months or years ago.
Well written commit messages make reviewing code much easier, and more enjoyable.
They also make interacting with the log easier — commands like blame, revert,
rebase, and log.
Here is an excellent summary of best-practice, following established conventions. It’s well worth a read but the key points are given below:
- Separate the subject from body with a blank line
- Limit the subject line to 50 characters
- Capitalize the subject line
- Do not end the subject line with a period
- Use the imperative mood in the subject line
- Wrap the body at 72 characters
- Use the body to explain what and why vs. how
Commit anything that cannot be automatically recreated
Typically we use version control to save anything that we create manually
e.g. source code, scripts, notes, plain-text documents, LaTeX documents.
Anything that we create using a compiler or a tool e.g. object files (.o,
.a, .class, .pdf, .dvi etc), binaries (exe files), libraries (dll
or jar files) we don’t save as we can recreate it from the source. Adopting
this approach also means there’s no risk of the auto-generated files becoming
out of sync with the manual ones.
We can automatically ignore such files using a .gitignore file.
See hints and tips.
When to commit changes?
- Commit frequently.
- There are no hard and fast rules, but good commits are atomic - they are the smallest change that remain meaningful.
- In the same way that it is wise to frequently save a document that you are working on, so too is it wise to save numerous revisions of your files. More frequent commits increase the granularity of your “undo” button.
- Small commits also help to avoid large merge conflicts.
- Test before you commit
- Don’t commit changes until you’ve tested that your code works.
- Non-working code should be fixed before you commit.
- Don’t commit unfinished work
- Break your code changes into small, but working chunks.
- If you need to temporarily save some work-in-progress
(e.g. in order to work in another branch),
use
git stash– see hints and tips.
- Commit related changes.
- Confine your commit to directly related changes. If you fix two separate bugs, you should have two separate commits.
Key Points
Commit messages explain why changes were made, so make them clear and concise
Follow conventions to give a history that is both useful, and easy to read
Only commit files which can’t be automatically recreated
Branching
Overview
Teaching: 25 min
Exercises: 15 minQuestions
What is a branch?
How can I merge changes from another branch?
Objectives
Know what branches are and why you would use them
Understand how to merge branches
Understand how to resolve conflicts during a merge
What is a branch?
You might have noticed the term branch in status messages:
$ git status
On branch master
nothing to commit (working directory clean)
and when we wanted to get back to our most recent version of the repository, we
used git checkout master.
Not only can our repository store the changes made to files and directories, it
can store multiple sets of these, which we can use and edit and update in
parallel. Each of these sets, or parallel instances, is termed a branch and
master is Git’s default branch.
A new branch can be created from any commit. Branches can also be merged together.
Why are branches useful?
Suppose we’ve developed some software and now we want to
try out some new ideas but we’re not sure yet whether we’ll keep them. We
can then create a branch ‘feature1’ and keep our master branch clean. When
we’re done developing the feature and we are sure that we want to include it
in our program, we can merge the feature branch with the master branch.
This keeps all the work-in-progress separate from the master branch, which
contains tested, working code.
When we merge our feature branch with master git creates a new commit which contains merged files from master and feature1. After the merge we can continue developing. The merged branch is not deleted. We can continue developing (and making commits) in feature1 as well.
Branching workflows
One popular model is the Gitflow model:
- A
masterbranch, representing a released version of the code - A release branch, representing the beginnings of the next release - a branch where the code is still undergoing testing
- Various feature and/or developer-specific branches representing work-in-progress, new features, bug fixes etc
For example:
](../fig/feature-branch.svg)
There are different possible workflows when using Git for code development. If you want to learn more about different workflows with Git, have a look at this discussion on the Atlassian website.
Branching in practice
One of our colleagues wants to contribute to the paper but is not quite sure if it will actually make a publication. So it will be safer to create a branch and carry on working on this “experimental” version of the paper in a branch rather than in the master.
$ git checkout -b simulations
Switched to a new branch 'simulations'
We’re going to change the title of the paper and update the author list (adding John Smith). However, before we get started it’s a good practice to check that we’re working on the right branch.
$ git branch # Double check which branch we are working on
master
* simulations
The * indicates which branch we’re currently in. Now let’s make the changes to the paper.
$ gedit paper.md # Change title and add co-author
$ git add paper.md
$ git commit # "Modify title and add John as co-author"
If we now want to work in our master branch. We can switch back by using:
$ git checkout master
Switched to branch 'master'
Having written some of the paper, we have thought of a better title for
the master version of the paper.
$ gedit paper.md # Rewrite the title
$ git add paper.md
$ git commit # "Include aircraft in title"
Merging and resolving conflicts
We are now working on two papers: the main one in our master branch and the one
which may possibly be collaborative work in our “simulations” branch.
Let’s add another section to the paper to write about John’s simulations.
$ git checkout simulations # Switch branch
$ gedit paper.md # Add 'simulations' section
$ git add paper.md
$ git commit -m "Add simulations" paper.md
At this point let’s visualise the state of our repo, and we can see the diverged commit history reflecting the recent work on our two branches:
git log --graph --all --oneline --decorate
* 89d5c6e (simulations) Add simulations
* 05d393a Change title and add coauthor
| * (HEAD, master) bdebbe0 Include aircraft in title
|/
* 87a65e6 Explain motivation for research
* 6a48241 Cite previous work in introduction
* ed26351 Cite PCASP paper
* 7446b1d Start the introduction
* 4f572d5 Add title and author
After some discussions with John we decided that we will publish together,
hence it makes sense to now merge all that was authored together with John
in branch “simulations”.
We can do that by merging that branch with the master branch. Let’s try
doing that:
$ git checkout master # Switch branch
$ git merge simulations # Merge simulations into master
Auto-merging paper.md
CONFLICT (content): Merge conflict in paper.md
Automatic merge failed; fix conflicts and then commit the result.
Git cannot complete the merge because there is a conflict - if you recall, after creating the new branch, we changed the title of the paper on both branches. We have to resolve the conflict and then complete the merge. We can get some more detail
$ git status
On branch master
You have unmerged paths.
(fix conflicts and run "git commit")
Unmerged paths:
(use "git add <file>..." to mark resolution)
both modified: paper.md
Let’s look inside paper.md:
# Title
<<<<<<< HEAD
Aircraft measurements of biomass burning aerosols over West Africa
=======
Simulations of biomass burning aerosols over West Africa
>>>>>>> simulations
The mark-up shows us the parts of the file causing the conflict and the versions they come from. We now need to manually edit the file to resolve the conflict. This means removing the mark-up and doing one of:
-
Keep the current version, which is the one marked-up by HEAD i.e. “Aircraft measurements of biomass burning aerosols over West Africa”
-
Keep the version from the other branch, which is the one marked-up by simulations i.e. “Simulations of biomass burning aerosols over West Africa”
-
Or manually edit the line to something new which might combine some elements of the two e.g. “Aircraft measurements and simulations of biomass burning aerosols over West Africa”
We edit the file. Then commit our changes:
$ gedit paper.md # Resolve conflict by editing paper.md
$ git add paper.md # Let Git know we have resolved the conflict
$ git commit
This is where version control proves itself better than DropBox or GoogleDrive, this ability to merge text files line-by-line and highlight the conflicts between them, so no work is ever lost.
We can see the two branches merged if we take another look at the log graph:
$ git log --graph --decorate --all --oneline
* 39cc80d (HEAD, master) Merge branch 'simulations'
|\
| * 89d5c6e (simulations) Add simulations
| * 05d393a Change title and add coauthor
* | bdebbe0 Include aircraft in title
|/
* 87a65e6 Explain motivation for research
* 6a48241 Cite previous work in introduction
* ed26351 Cite PCASP paper
* 7446b1d Start the introduction
* 4f572d5 Add title and author
Looking at our history - revisited
We already looked at “going back in time with Git”. But now we’ll look at it in more detail to see how moving back relates to branches and we will learn how to actually undo things. So far we were moving back in time in one branch by checking out one of the past commits.
But we were then in the “detached HEAD” state.
Add a commit to detached HEAD
- Checkout one of the previous commits from our repository.
- Make some changes and commit them. What happened?
- Now try to run
git branch. What can you see?Solution
git checkout HEAD~1 # Check out the commit one before last gedit paper.md # Make some edits git add paper.md # Stage the changes git commit # Commit the changes git branch # You should see a message like the one below, # indicating your commit does not belong to a branch* (detached from 57289fb) masterYou have just made a commit on a detached HEAD – as you can see from the output above, a new temporary branch has been created, which doesn’t have a name.
See this [detached HEAD animation] of the above process.
[detached HEAD animation]: https://learngitbranching.js.org/?NODEMO&command=git%20checkout%20HEAD~;git%20commit
Abandon the commit on a detached HEAD
You decide that you want to abandon that commit. How would you get back to the current version of your project?
Solution
git checkout masterGit will warn you that you are leaving behind changes that would be lost:
The output you see will be slightly different to that below, reflecting your previous commit message and commit ID.
Warning: you are leaving 1 commit behind, not connected to any of your branches: eb7c650 Add empty line for branching exercise If you want to keep them by creating a new branch, this may be a good time to do so with: git branch new_branch_name eb7c650 Switched to branch 'master' Your branch is up-to-date with 'master'.See this abandon detached HEAD animation.
Save your changes in a new branch
Preparation:
- You should be on the
masterbranch after that last exercise. If not, check out master again:git checkout master- Checkout one of the previous commits from your repository.
- Make some changes, save the file(s), and make a commit on the detached HEAD as you did in the first exercise.
- Run
git branchto list your local branches, and see that you are on a temporary branch.This time we want to keep the commit rather than abandon it.
- Create a new branch and check it out.
- Now run
git logand see that your new commit belongs to this new branch.- List your local branches again and see that the temporary branch has gone.
- Switch back to (i.e. checkout) the
masterbranchSolution
git checkout HEAD~1 # Checkout the commit before last gedit paper.md # Modify one of your files git commit -a # Commit all the modified files git branch # List local branches* (HEAD detached from f908519) master simulationsYou are currently on a temporary, unnamed branch, as indicated by the
*.git branch dh-exercise # Create a new branch git checkout dh-exercise # Switch to the new branchSwitched to a new branch 'dh-exericise'git branch # View local branches* dh-exericise master simulationsThe commit you made on the detached HEAD now belongs to a named branch (
dh-exercisein the example above), rather than a temporary branch.git checkout master # Switch back to the 'master' branchSee this new branch animation for the key points in this exercise.
Key Points
git branchcreates a new branchUse feature branches for new ideas and fixes, before merging into
mastermerging does not delete any branches
Lunch break
Overview
Teaching: min
Exercises: minQuestions
Objectives
Key Points
Undoing changes
Overview
Teaching: 25 min
Exercises: 0 minQuestions
How can I discard unstaged changes?
How do I edit the last commit?
How can I undo a commit?
Objectives
Be able to discard unstaged changes
Be able to amend the most recent commit
Be able to discard all changes since a particular commit
Be able to undo the changes introduced by a commit
There are a number of things which we can amend and change after they have been commited in Git.
Discarding local changes
Maybe we made our change just to see how something looks, or to
quickly try something out. But we may be unhappy with our changes. If we
haven’t yet done a git add we can just throw the changes away and return
our file to the most recent version we committed to the repository by using:
$ gedit paper.md # Make some small edits to the file
$ git checkout paper.md # Discard edits we just made
and we can see that our file has reverted to being the most up-to-date one in the repository:
$ git status # See that we have a clean working directory
$ gedit paper.md # Inspect file to verify changes have been discarded
Amending the most recent commit
If you just made a commit and realised that either you did it a bit too early
and the files are not yet ready to be commited. Or, which is not as uncommon as
you think, your commit message is not as it is supposed to be. You can fix that
using the command git commit --amend
This opens up the default editor for Git which includes the previous commit message - you can edit it and close the editor. This will simply fix the commit message.
But what if we forgot to include some files in the commit?
Let’s try it on our example. First, let’s modify two files: our paper file and the references file. We will add a methodology section to the paper where we detail the model used for the simulations, and add a reference for this to the references file.
$ gedit paper.md # Add methodology section, including a reference to model
$ gedit refs.txt # Add new reference for the model used
$ git status # Get a status update on file modifications
$ On branch master
Changes not staged for commit:
(use "git add <file>..." to update what will be committed)
(use "git checkout -- <file>..." to discard changes in working directory)
modified: refs.txt
modified: paper.md
no changes added to commit (use "git add" and/or "git commit -a")
Let’s then add and commit paper.md but not the references file.
$ git add paper.md # Add paper to staging area
$ git commit -m "Describe methodology"
Let’s have a look at our working directory now:
$ git status
$ On branch master
Changes not staged for commit:
(use "git add <file>..." to update what will be committed)
(use "git checkout -- <file>..." to discard changes in working directory)
modified: refs.txt
no changes added to commit (use "git add" and/or "git commit -a")
Also, run git log -2 to see what is the latest commit message and ID.
Now, we want to fix our commit and add the references file.
$ git add refs.txt # Add reference file
$ git commit --amend # Amend most recent commit
This will again bring up the editor and we can amend the commit message if required.
Now when we run git status and then git log we can see that our Working
Directory is clean and that both files were added.
$ git status
$ git log -3
git revert (undo changes associated with a commit)
git revert removes the changes applied in a specified commit. However, rather
than deleting the commit from history, git works out how to undo those changes
introduced by the commit, and appends a new commit with the resulting content.
Let’s try it on our example. Modify the paper, describing the SMPS which is another instrument used to measure particle sizes, and then make a commit.
$ gedit paper.md # Describe other instrument
$ git add paper.md
$ git commit -m "Describe SMPS"
We now realise that what we’ve just done in our journal article is incorrect because we are not using the data from that instrument. Some of the data got corrupted, and due to problems with the logging computer we are not going to use that data. So it makes sense to abandon the commit completely.
$ git revert HEAD # Undo changes introduced by most recent commit
When we revert, a new commit is created. The HEAD pointer and the branch pointer are in fact moved forward rather than backwards.
We can revert any previous commit. That is, we can “abandon” any of the previous changes. However, depending on the changes we have made since, we may bump into a conflict (which we will cover in more detail later on). For example:
error: could not revert 848361e... Describe SMPS
hint: after resolving the conflicts, mark the corrected paths
hint: with 'git add <paths>' or 'git rm <paths>'
hint: and commit the result with 'git commit'
Behind the scenes Git gets confused trying to merge the commit HEAD is pointing to with the past commit we’re reverting.
So we have seen that git revert is a non-destructive way to undo a commit.
What if we don’t want to keep a record of undoing commits? That would give a neater
history. git reset can also be used to undo commits, but it does so by deleting
history.
git reset --hard (restore a previous state by deleting history)
git reset has several uses, and is most often used to unstage files from the staging
area i.e. git reset or git reset <file>.
We are going to use a variant git reset --hard <commit> to reset things to how
they were at <commit>. This is a permanent undo which deletes all changes more recent
than <commit> from your history. There is clearly potential here to lose work, so use
this command with care.
Let’s try that on our paper, using the same example as before. Now we have two commits which we want to abandon: the commit outlining the unreliable instrumentation, and the subsequent revert commit. We can achieve this by resetting to the last commit we want to keep.
We can do that by running:
$ git reset --hard HEAD~2 # Move tip of branch to two commits before HEAD
HEAD is now at fbdc44b Add methodology section and update references file
This moves the tip of the branch back to the specified commit. If we look in-depth,
this command moves back two pointers: HEAD and the pointer to the tip of the
branch we currently are working on (master). (HEAD~ = the commit right before HEAD;
HEAD~2 = two commits before HEAD)
The final effect is what we need: we abandoned the commits and we are now back to where we were before making the commit about the data we are not using.
Click for an animation of the revert and reset operations we just used.
This article discusses more in
depth git reset showing the differences between the three options:
--soft--mixed--hard
Top tip: do not use
git resetwith remote branchesThere is one important thing to remember about the
resetcommand - it should only be used with branches that have not been shared yet (that is they haven’t been pushed into a remote repository that others are using). Resetting is changing the history without leaving trace. This is always a bad practice when using remote repositories and can lead to a horrible mess.Reverting records the fact of “abandoning the commit” in the history. When we revert in a branch that is shared with others and then push that branch into the remote repository, it is as if we “came clean” about what we were doing. Everyone who pulls the branch in which we reverted changes will see it. With
git resetwe “keep it secret” that we have undone some changes.As such, if we want to abandon changes in branches that are shared with others, we should to use the
revertcommand.

See this Atlassian online tutorial
for further reading about the differences between git revert and git reset.
How to undo almost anything with Git
See this blog post for more example scenarios and how to recover from them.
Key Points
git checkout <file>discards unstaged changes
git commit --amendallows you to edit the last commit
git revertundoes a commit, preserving history
git resetundoes a commit by deleting history
Working from multiple locations with a remote repository
Overview
Teaching: 25 min
Exercises: 0 minQuestions
What is a remote repository
How can I use GitHub to work from multiple locations?
Objectives
Understand how to set up remote repository
Understand how to push local changes to a remote repository
Understand how to clone a remote repository
We’re going to set up a remote repository that we can use from multiple locations. The remote repository can also be shared with colleagues, if we want to.
GitHub
GitHub is a company which provides remote repositories for Git and a range of functionalities supporting their use. GitHub allows users to set up their private and public source code Git repositories. It provides tools for browsing, collaborating on and documenting code. GitHub, like other services such as Launchpad, Bitbucket, GoogleCode, and SourceForge supports a wealth of resources to support projects including:
- Time histories changes to repositories
- Commit-triggered e-mails
- Browsing code from within a web browser, with syntax highlighting
- Software release management
- Issue (ticket) and bug tracking
- Download
- Varying permissions for various groups of users
- Other service hooks e.g. to Twitter.
Note GitHub’s free repositories have public licences by default. If you don’t want to share (in the most liberal sense) your stuff with the world and you want to use GitHub, you will need to pay for the private GitHub repositories (GitHub offers up to 5 free private repositories, if you are an academic - but do check this information as T&C may change).
GitHub for research
GitHub isn’t the only remote repositories provider. It is however very popular, in particular within the Open Source communities. The reason why we teach GitHub in this tutorial is mainly due to popular demand.
Also, GitHub has started working on functionality which is particularily useful for researchers such as making code citable.
Get an account
Let’s get back to our tutorial. We will first need a GitHub account.
Sign up or if you already have an account sign in.
Set up SSH keys
SSH is an encrypted network protocol which we will use to securely access our remote repository. In order to use it, we need to set up a pair of SSH keys, which are used together to validate access. There’s a private key, and a public key - GitHub needs to know the public key, but the private key stays only on your computer. A useful analogy is to think of the public key as a padlock, and the private key as the only key to the padlock.
Create ssh keys
Let’s first check whether we already have ssh keys set up:
$ ls ~/.ssh
If you already have ssh keys set up, your output will look something like this:
id_ed25519 id_ed25519.pub
and you can jump to the final step.
If you still need to set up ssh keys, you’ll get a message like this:
ls: cannot access '/home/yourusername/.ssh': No such file or directory
To set up the key pair, we use the following command
$ ssh-keygen -t ed25519 -C "your_email@example.com"
You might get an error from this if your system doesn’t support
the ed25519 algorithm, in which case you can try
$ ssh-keygen -t rsa -b 4096 -C "your_email@example.com"
Generating public/private ed25519 key pair.
Enter file in which to save the key (/home/you/.ssh/id_ed25519):
Accept the default option using Enter.
Created directory '/home/you/.ssh'.
Enter passphrase (empty for no passphrase):
Enter a password (you’ll be prompted to enter it twice)
Your identification has been saved in /home/you/.ssh/id_ed25519
Your public key has been saved in /home/you/.ssh/id_ed25519.pub
The key fingerprint is:
SHA256:SMSPIStNyA00KPxuYu94KpZgRAYjgt9g4BA4kFy3g1o your_email@example.com
The key's randomart image is:
+--[ED25519 256]--+
|^B== o. |
|%*=.*.+ |
|+=.E =.+ |
| .=.+.o.. |
|.... . S |
|.+ o |
|+ = |
|.o.o |
|oo+. |
+----[SHA256]-----+
Now that we have generated the SSH keys, we will find the SSH files when we check.
$ ls ~/.ssh
id_ed25519 id_ed25519.pub
We can view the public key using
$ cat ~/.ssh/id_ed25519.pub
ssh-ed25519 AAAAC3NzaC1lZDI1NTE5AAAAIDmRA3d51X0uu9wXek559gfn6UFNF69yZjChyBIU2qKI your_email@example.com
Now you should copy the output from this command ready for the final step.
Add public ssh key to GitHub
The final step is to add the public key to our GitHub accounts.
- On GitHub, click on your profile icon in the top right corner
- Click “Settings,” then on the settings page
- Click “SSH and GPG keys”
- Click the “New SSH key” button on the right side.
- Add a title e.g. “my_work_laptop” and paste your SSH key into the field, and click the “Add SSH key” to complete the setup.
Set the default GitHub branch name to ‘master’
As we saw in episode 2, the default branch name in a git repo is master.
In 2021 GitHub and many other remote repo providers changed their settings so that new repositories will use main instead of master. As ever there are arguments for and against this change. We can however choose the default branch name in our GitHub settings, so let’s set it to master to be consistent with the git software itself.
On GitHub, click on your profile photo at the top right of the page. Then go to Settings -> Repositories -> Repository default branch.
Change ‘main’ to ‘master’ and click ‘update’.
Create a new repository
Now, we can create a repository on GitHub,
- Log in to GitHub
- Click on the Create icon on the top right
- Enter Repository name: “paper”
- For the purpose of this exercise we’ll create a public repository
- Make sure that Initialize this repository with a README is unselected
- Click Create Repository
You’ll get a page with new information about your repository. We already have our local repository and we will be pushing it to GitHub using SSH, so this is the option we will use:
$ git remote add origin git@github.com:<USERNAME>/paper.git
$ git push -u origin master
The first line sets up an alias origin, to correspond to the URL of our
new repository on GitHub.
Push locally tracked files to a remote repository
Now copy and paste the second line,
$ git push -u origin master
Counting objects: 32, done.
Delta compression using up to 8 threads.
Compressing objects: 100% (28/28), done.
Writing objects: 100% (32/32), 3.29 KiB | 0 bytes/s, done.
Total 32 (delta 7), reused 0 (delta 0)
To https://github.com/gcapes/paper.git
* [new branch] master -> master
Branch master set up to track remote branch master from origin.
This pushes our master branch to the remote repository, named via the alias
origin and creates a new master branch in the remote repository.
Now, on GitHub, we should see our code and if we click the Commits tab we should see
our complete history of commits.
Our local repository is now available on GitHub. So, anywhere we can access GitHub, we can access our repository.
Push other local branches to a remote repository
Let’s push each of our local branches into our remote repository:
$ git push origin branch_name
The branch should now be created in our GitHub repository.
To list all branches (local and remote):
$ git branch -a
Deleting branches (for information only)
Don’t do this now. This is just for information. To delete branches, use the following syntax:
$ git branch -d <branch_name> # For local branches $ git push origin --delete <branch_name> # For remote branches
Cloning a remote repository
Now that we have a copy of the repo on GitHub,
we can download or git clone a fresh copy to work on from another computer.
So let’s pretend that the repo we’ve been working on so far is on a PC in the office, and you want to do some work on your laptop at home in the evening.
Before we clone the repo, we’ll navigate up one directory so that we’re not already in a git repo.
cd ..
Then to clone the repo into a new directory called laptop_paper
$ git clone https://github.com/<USERNAME>/paper.git laptop_paper
Cloning into 'laptop_paper'...
remote: Counting objects: 32, done.
remote: Compressing objects: 100% (21/21), done.
remote: Total 32 (delta 7), reused 32 (delta 7), pack-reused 0
Unpacking objects: 100% (32/32), done.
Checking connectivity... done.
Cloning creates an exact copy of the repository. By deafult it creates
a directory with the same name as the name of the repository.
However, we already have a paper dircectory,
so have specified that we want to clone into a new directory laptop_paper.
Now, if we cd into laptop_paper we can see that we have our repository,
$ cd laptop_paper
$ git log
and we can see our Git configuration files too:
$ ls -A
In order to see the other branches locally, we can check them out as before:
$ git branch -r # Show remote branches
$ git checkout simulations # Check out the simulations branch
Push changes to a remote repository
We can use our cloned repository just as if it was a local repository so let’s add a results section and commit the changes.
$ git checkout master # We'll continue working on the master branch
$ gedit paper.md # Add results section
$ git add paper.md # Stage changes
$ git commit
Having done that, how do we send our changes back to the remote repository? We can do this by pushing our changes,
$ git push origin master
If we now check our GitHub page we should be able to see our new changes under the Commit tab.
To see all remote repositories (we can have multiple!) type:
$ git remote -v
Key Points
Git is the version control system: GitHub is a remote repositories provider.
git cloneto make a local copy of a remote repository
git pushto send local changes to remote repository
Collaborating with a remote repository
Overview
Teaching: 25 min
Exercises: 15 minQuestions
How do I update my local repository with changes from the remote?
How can I collaborate using Git?
Objectives
Understand how to pull changes from remote repository
Understand how to resolve merge conflicts
Pulling changes from a remote repository
Having a remote repository means we can share it and collaborate with others (or even just continue to work alone but from multiple locations). We’ve seen how to clone the whole repo, so next we’ll look at how to update our local repo with just the latest changes on the remote.
We were in the laptop_paper directory at the end of the last episode,
having pushed one commit to the remote.
Let’s now change directory to the other repository paper,
and git pull the commit from the remote.
$ cd ../paper
$ git pull origin master
We can now view the contents of paper.md and check the log to confirm we have
the latest commit from the remote:
$ git log -2
Still in the paper directory, let’s add a figures section to paper.md,
commit the file and push these changes to GitHub:
$ gedit paper.md # Add figures section
$ git add paper.md
$ git commit -m "Add figures"
$ git push
Now let’s change directory to our other repository and fetch the commits from our
remote repository,
$ cd ../laptop_paper # Switch to the other directory
$ git fetch
git fetch doesn’t change any of the local branches,
it just gets information about what commits are on the remote branches.
We can visualise the remote branches in the same way as we did for local branches, so let’s draw a network graph before going any further:
git log --graph --all --decorate --oneline
* 7c239c3 (origin/master, origin/HEAD) Add figures
* 0cc2a2d (HEAD -> master) Discuss results
* 3011ee0 Describe methodology
* 6420699 Merge branch 'simulations'
|\
| * 7138785 (origin/simulations) Add simulations
| * e695fa8 Change title and add coauthor
* | e950911 Include aircraft in title
|/
* 0b28b0a Explain motivation for research
* 7cacba8 Cite previous work in introduction
* 56781f4 Cite PCASP paper
* 5033467 Start the introduction
* e08262e Add title and author
As expected, we see that the origin/master branch is ahead of our local master branch
by one commit — note that the history hasn’t diverged,
rather our local branch is missing the most recent commit on origin/master.
We can now see what the differences are by doing,
$ git diff origin/master
which compares our master branch with the origin/master branch
which is the name of the master branch in origin which is the alias for our
cloned repository, the one on GitHub.
We can then merge these changes into our current repository,
but given the history hasn’t diverged, we don’t get a merge commit —
instead we get a fast-forward merge.
$ git merge origin/master
Updating 0cc2a2d..7c239c3
Fast-forward
paper.md | 4 ++++
1 file changed, 4 insertions(+)
If we look at the network graph again, all that has changed
is that master now points to the same commit as origin/master.
git log --graph --all --decorate --oneline -4
* 7c239c3 (HEAD -> master, origin/master, origin/HEAD) Add figures
* 0cc2a2d Discuss results
* 3011ee0 Describe methodology
* 6420699 Merge branch 'simulations'
We can inspect the file to confirm that we have our changes.
$ cat paper.md
So we have now used two slightly different methods to get the latest changes
from the remote repo.
You may already have guessed that git pull is a shorthand for git fetch followed by
git merge.
FetchvspullIf
git pullis a shortcut forgit fetchfollowed bygit mergethen, why would you ever want to do these steps separately?Well, depending on what the commits on the remote branch contain, you might want to abandon your local commits before merging (e.g. your local commits duplicate the changes on the remote), rebase your local branch to avoid a merge commit, or something else.
Fetching first lets you inspect the changes before deciding what you want to do with them.
Let’s write the conclusions:
$ gedit paper.md # Write Conclusions
$ git add paper.md
$ git commit -m "Write Conclusions" paper.md
$ git push origin master
$ cd ../paper # Switch back to the paper directory
$ git pull origin master # Get changes from remote repository
This is the same scenario as before, so we get another fast-forward merge.
We can check that we have our changes:
$ cat paper.md
$ git log
Conflicts and how to resolve them
Let’s continue to pretend that our two local repositories are hosted on two different machines. You should still be in the original paper folder. Add an affiliation for each author. Then push these changes to our remote repository:
$ gedit paper.md # Add author affiliations
$ git add paper.md
$ git commit -m "Add author affiliations"
$ git push origin master
Now let us suppose, at a later date, we use our other repository (on the laptop) and we want to change the order of the authors.
The remote branch origin/master is now ahead of our local master branch on the laptop,
because we haven’t yet updated our local branch using git pull.
$ cd ../laptop_paper # Switch directory to other copy of our repository
$ gedit paper.md # Change order of the authors
$ git add paper.md
$ git commit -m "Change the first author" paper.md
$ git push origin master
To https://github.com/<USERNAME>/paper.git
! [rejected] master -> master (fetch first)
error: failed to push some refs to 'https://github.com/<USERNAME>/paper.git'
hint: Updates were rejected because the remote contains work that you do
hint: not have locally. This is usually caused by another repository pushing
hint: to the same ref. You may want to first integrate the remote changes
hint: (e.g., 'git pull ...') before pushing again.
hint: See the 'Note about fast-forwards' in 'git push --help' for details.
Our push fails, as we’ve not yet pulled down our changes from our remote repository. Before pushing we should always pull, so let’s do that…
$ git pull origin master
and we get:
Auto-merging paper.md
CONFLICT (content): Merge conflict in paper.md
Automatic merge failed; fix conflicts and then commit the result.
As we saw earlier, with the fetch and merge, git pull pulls down changes from the
repository and tries to merge them. It does this on a file-by-file basis,
merging files line by line. We get a conflict if a file has changes that
affect the same lines and those changes can’t be seamlessly merged. We had this
situation before in the branching episode when we merged a feature branch into master.
If we look at the status,
$ git status
we can see that our file is listed as Unmerged and if we look at paper.md, we see something like:
<<<<<<< HEAD
Author
G Capes, J Smith
=======
author
J Smith, G Capes
>>>>>>> 1b55fe7f23a6411f99bf573bfb287937ecb647fc
The mark-up shows us the parts of the file causing the conflict and the versions they come from. We now need to manually edit the file to resolve the conflict. Just like we did when we had to deal with the conflict when we were merging the branches.
We edit the file. Then commit our changes. Now, if we push …
$ gedit paper.md # Edit file to resolve merge conflict
$ git add paper.md # Stage the file
$ git commit # Commit to mark the conflict as resolved
$ git push origin master
… all goes well. If we now go to GitHub and click on the “Overview” tab we can see where our repository diverged and came together again.
This is where version control proves itself better than DropBox or GoogleDrive, this ability to merge text files line-by-line and highlight the conflicts between them, so no work is ever lost.
We’ll finish by pulling these changes into other copy of the repo, so both copies are up to date:
$ cd ../paper # Switch to 'paper' directory
$ git pull origin master # Merge remote branch into local
Collaborating on a remote repository
In this exercise you should work with a partner or a group of three. One of you should give access to your remote repository on GitHub to the others (by selecting
Settings -> Manage access -> Invite a collaborator). The invited person should then check their email to accept the invitation.Now those of you who are added as collaborators should clone the repository of the first person on your machines. (make sure that you don’t clone into a directory that is already a repository!)
Each of you should now make some changes to the files in the repository e.g. fix a typo, add a file containing supplementary material. Commit the changes and then push them back to the remote repository. Remember to pull changes before you push.
Creating branches and sharing them in the remote repository
Working with the same remote repository, each of you should create a new branch locally and push it back to the remote repo.
Each person should use a different name for their local branch. The following commands assume your new branch is called
my_branch, and your partner’s branch is calledtheir_branch— you should substitute the name of your new branch and your partner’s new branch.$ git checkout -b my_branch # Create and check out a new branch. # Substitute your local branch name for 'my_branch'.Now create/edit a file (e.g. fix a typo, add supplementary material etc), and then commit your changes.
$ git push origin my_branch # Push your new branch to remote repo.The other person should check out local copies of the branches created by others (so eventually everybody should have the same number of branches as the remote repository).
To fetch new branches from the remote repository (into your local
.gitdatabase):$ git fetch originCounting objects: 3, done. remote: Compressing objects: 100% (3/3), done. remote: Total 3 (delta 0), reused 2 (delta 0) Unpacking objects: 100% (3/3), done. From https://github.com/gcapes/paper 9e1705a..640210a master -> origin/master * [new branch] their_branch -> origin/their_branchYour local repository should now contain all the branches from the remote repository, but the
fetchcommand doesn’t actually update your local branches.The next step is to check out a new branch locally to track the new remote branch.
$ git checkout their_branchBranch their_branch set up to track remote branch their_branch from origin. Switched to a new branch 'their_branch'
Undoing changes using revert
Once you have the branches which others created, try to undo one of the commits.
Each one of you should try to revert a commit in a different branch to your partner(s).
Push the branch back to the remote repository. The others should pull that branch to get the changes you made.
What is the end result? What happens when you pull the branch that your colleagues changed using
git revert?Solution
The revert shows up in everyone’s copy. You should always use
revertto undo changes which have been shared with others.
Key Points
git pullto integrate remote changes into local copy of repository
Rebasing
Overview
Teaching: 25 min
Exercises: 0 minQuestions
What is rebasing?
Objectives
Understand what is meant by rebasing
Understand the difference between merging and rebasing
When (and when not) to rebase
We were in the paper directory at the end of the last episode, which is where this episode continues.
Let’s review the recent history of our project,
noting particularly the commit message which results when origin/master and master diverge,
and origin/master is merged back into master.
$ git log --graph --all --oneline --decorate -6
* 365748e (HEAD -> master, origin/master, origin/HEAD) Merge branch 'master' of github.com:gcapes/paper
|\
| * ff18da4 Add author affiliations
* | 8f44540 Change first author
|/
* 8494909 Write conclusions
* e90a501 Add figures
* 3011ee0 Discuss results
Normally a merge commit indicates that a feature branch has been completed, a bug has been fixed, or marks a release version of our project. Our most recent merge commit doesn’t mark any real milestone in the history of the project — all it tells us is that we didn’t pull before we tried to push. Merge commits like this don’t add any real value1, and can quickly clutter the history of a project.
If only there were a way to avoid them, e.g. by starting with the tip of the remote branch and reapplying our local commits from this new starting point. You could also describe this as moving the local commits onto a new base commit i.e. rebasing.
What is it?
Rebasing is the process of moving a whole branch to a new base commit. Git takes your changes, and “replays” them onto the new base commit. This creates a brand new commit for each commit in the original branch. As such, your history is rewritten when you rebase.
It’s like saying “add my changes to what has already been done”.
](../fig/git-rebase.svg)
How’s that different to merging?
Imagine you create a new feature branch to work in, and meanwhile there have been
commits added to the master branch, as shown below.

You’ve finished working on the feature, and
you want to incorporate your changes from the feature branch into the master branch.
You could merge directly or rebase then merge. We have already encountered merging, and it
looks like this:

The main reason you might want to rebase is to maintain a linear project history.
In the example above, if you merge directly (recall that there are new commits on
both the master branch and feature branch), you have a 3-way merge
(common ancestor, HEAD and MERGE_HEAD) and a merge commit results.
Note that you get a merge commit whether or not there are any merge conflicts.
If you rebase, your commits from the feature branch are replayed onto master,
creating brand new commits in the process.
If there are any merge conflicts, you are prompted to resolve these.

After rebasing, you can then perform a fast-forward merge into master i.e. without
an extra merge commit at the end, so you have a nice clean linear history.

Why would I consider rebasing?
Rebase and merge solve the same problem: integrating commits from one branch into another.
Which method you use is largely personal preference.
Some reasons to consider rebasing:
- To give a linear project history, which is easier to follow
- This makes using
git log, andgit bisecteasier
- This makes using
- To integrate upstream changes into your local repository, without creating any merge commits
- To keep a feature branch up to date with master, without polluting your feature branch with extraneous merge commits
- Makes pull requests easier to manage (because you’ve already resolved any merge conflicts while rebasing)
- To tidy up a feature branch before merging into master (requires interactive rebase)
Interactive rebasing
git rebase -iwill open an interactive rebasing session. This provides an opportunity to edit, delete, combine, and reorder individual commits as they are moved onto the new base commit. This can be useful for cleaning up history before sharing it with others.
A worked example using git rebase <base>
We’ll repeat the scenario from the last episode where the local and remote branches diverge,
but instead of merging the remote branch origin/master into master,
we’ll rebase master onto origin/master.
We’ll write some acknowledgements, then commit and push.
$ gedit paper.md # Write acknowledgements
$ git add paper.md
$ git commit -m "Write acknowledgements section"
$ git push origin master # Push master branch to remote
We’ll now switch machine to our laptop, and write the abstract:
$ cd ../laptop_paper # Pretend we're on the laptop
$ gedit paper.md # Add abstract section
$ git add paper.md
$ git commit # "Write abstract"
At this point we can view a graph of project history,
and see where the master branch diverges from origin/master:
$ git fetch # Retrieve information about remote branches
$ git log --graph --all --oneline --decorate # View project history before rebasing
* 21cfe5f (HEAD -> master) Write abstract
| * 13aa7e3 (origin/master, origin/HEAD) Add acknowledgements
|/
* 365748e Merge branch 'master' of github.com:gcapes/paper
|\
| * ff18da4 Add author affiliations
* | 8f44540 Change first author
|/
* 8494909 Add figures
As before, if we try to push our local branch, it will fail —
git will suggest that we pull in order to merge the remote commit into our local branch,
before pushing again.
We did that in the last episode, which resulted in a ‘forgot-to-pull’ merge commit.
This time we will replay our local branch onto to the remote branch.
$ git rebase origin/master # Rebase current branch onto origin/master
Note that this syntax only works because we just did a git fetch.
Typically, you would use git pull --rebase instead, which combines the fetch and rebase steps.
Merge conflicts during a rebase
Depending what changes we have made, there may be conflicts we have to fix in order to rebase. If this is the case, Git will let us know, and give some instructions on how to proceed. The process for fixing conflicts is the same as before:
$ gedit file # Manually fix conficts in affected file(s) $ git add file # Mark file(s) as resolved $ git rebase --continue # Continue to rebase
Let’s now visualise our project history again, having rebased master onto origin/master,
and observe that we now have a linear project history.
Rebasing has created a new commit (with a new commit ID) and put it on top of
the commit pointed at by origin/master — thus avoiding that forgot-to-pull merge commit!
$ git log --graph --all --oneline --decorate # View project history after rebasing
* 6105e61 (HEAD -> master) Write abstract
* 13aa7e3 (origin/master, origin/HEAD) Add acknowledgements
* 365748e Merge branch 'master' of github.com:gcapes/paper
|\
| * ff18da4 Add author affiliations
* | 8f44540 Change first author
|/
* 8494909 Add figures
Having integrated the remote changes into our local branch, we can now push our local branch back to ‘origin’.
$ git push origin master
This online tutorial gives a good illustration of what happens during rebasing.
Warning: the perils of rebasing
The main rule is: do not rebase branches shared with other contributors. Rebasing changes history and as with practically any Git command which changes history, it should be used with care.
The branches that are pushed to remote repositories should always be merged. For your local branches that you never share, you may use rebasing. Rebasing is convenient if you want to keep a clean history. It also helps to avoid conflicts in the long run. But again, it is considered a better practice to use merge and deal with conflicts rather than mess up shared branches using rebase.
-
This statement contains elements of opinion. ↩
Key Points
rebaseapplies your changes on top of a new base (parent) commitrebasing rewrites history
Pull Requests
Overview
Teaching: 5 min
Exercises: 10 minQuestions
How can I contribute to a repository to which I don’t have write access?
Objectives
Understand what it means to fork a repository
Be able to fork a repository on GitHub
Understand how to submit a pull request
Pull Requests are a great solution for contributing to repositories to which you don’t have write access. Adding other people as collaborators to a remote repository is a good idea but sometimes (or even most of the time) you want to make sure that their contributions will provide more benefits than the potential mistakes they may introduce.
In large projects, primarily Open Source ones, in which the community of contributors can be very big, keeping the source code safe but at the same allow people to make contributions without making them “pass” tests for their skills and trustworthiness may be one of the keys to success.
Leveraging the power of Git, GitHub provides a functionality called Pull Requests. Essentially it’s “requesting the owner of the repository to pull in your contributions”. The owner may or may not accept them. But for you as a contributor, it was really easy to make the contribution.
The process
- Find a repository on GitHub that belongs to someone else
- Fork it (
git cloneit on GitHub’s servers into your GitHub account) git cloneit to your PC/laptop- Create a new branch
- Make changes, and push them to your repository on GitHub
- Request that the owner of the repository you forked pulls in your changes
](../fig/github-diagram.png)
Advice for submitting Pull Requests
- Keep your Pull Request small and focussed (makes it easier to process)
- Submit one PR per issue
- Create a separate branch for each issue you work on (you can submit a PR from any branch)
- R.T.F.M.
- If the repository has contributing guidelines, read them, and follow the guidance. This gives your PR a better chance of being accepted.
- Some repositories pre-populate the body of the PR or issue message
with a template.
- Follow the instructions (e.g. provide the information requested)
- Consider creating a new issue first to discuss your ideas before submitting a PR. Some repositories ask for this in their contributing guidelines, but this can be a good approach even if it isn’t required, so that you know whether the owner agrees with your suggestion, and might bring up ideas and/or challenges you haven’t considered.
After submitting your pull request
If things go well, your PR may get merged just as it is. However, for most PRs, you can expect some discussion (on GitHub) and a request for further edits to be made. Given your changes haven’t been merged get, you can make changes either by adding further commits to your branch and pushing them, or you could consider rewriting your history neatly using an interactive rebase onto an earlier commit. In either case, your PR will update automatically once you have pushed your commits.
Exercise
Let’s look at the workflow and try to repeat it:
Fork this repository by clicking on the
Forkbutton at the top of the page.Clone the repository from YOUR GitHub account. When you run
git remote -vyou should get something like this:origin https://github.com/YOUR_USERNAME/manchester-paper.git(fetch) origin https://github.com/YOUR_USERNAME/manchester-paper.git(push)cdinto the directory you just cloned. Create a new branch, then make changes you want to contribute. Commit and push them back to your repository. You won’t be able to push back to the repository you forked from because you are not added as a contributor!- Go to your GitHub account and in the forked repository find a green button for creating Pull Requests. Click it and follow the instructions.
- The owner of the original repository gets a notification that someone created a pull request - the request can be reviewed, commented and merged in (or not) via GitHub.
Key Points
A
forkis agit cloneinto your (GitHub) accountA
pull requestasks the owner of a repository to incorporate your changes
Git hints and tips
Overview
Teaching: 15 min
Exercises: 0 minQuestions
How can I find help?
How can I further customise Git to suit my preferences?
Objectives
Access help online and from command prompt
Configure Git to ignore certain types of files
Understand how to build a commit selectively using
git add --patch
Getting help
man page
Like many Unix/Linux commands, git has a man page,
$ man git
You can scroll the manual page up and down using the up and down arrows.
You can search for keywords by typing / followed by the search term e.g. if
interested in help, type /help and then hit enter.
To exit the manual page, type q.
Command-line help
Type,
$ git --help
and Git gives a list of commands it is able to help with, as well as their descriptions.
You can get more help on a specific command, by providing the command name e.g.
$ git init --help
$ git commit --help
Search for your problem online. Someone has probably already asked (and answered) your question on stackoverflow.com.
Ignore scratch, temporary and binary files
You can create a .gitignore file which lists the patterns of files you want
Git to ignore. It’s common practice to not add to a repository any file you can
automatically create in some way e.g. C object files (.o), Java class
(.class) files or temporary files e.g. XEmacs scratch files (~). Adding
these to .gitignore means Git won’t complain about them being untracked.
Create or edit gitignore,
$ gedit .gitignore
Then add patterns for the files you want to ignore, where * is a wildcard,
*~ *.o *.so *.dll *.exe *.class *.jar
Then, add .gitignore to your repository,
$ git add .gitignore $ git commit -m "Added rules to ignore vim scratch
files and binary files"
git add --patch
This is a way to stage only parts of a file. If you have done lots of work without committing, it may be useful to commit your changes as a series of small commits. This command allows you to choose which changes go into which commit so you can group the changes logically.
- Guide to
git add --patch - Manually editing hunks is the most difficult aspect.
git commit --author
You can commit changes made by someone else, by using the --author
flag. Consider how this may enable you to collaborate with your colleagues.
The syntax is:
git add --author="FirstName Surname <Firstname.Surname@example.com>"
Colours in Git
On many computers, the terminal output is automatically coloured which makes reading the output easier. If your output is not coloured (e.g. in the Sackville/G11 cluster) there is a command which will add the colour (note the spelling of color):
$ git config --global --add color.ui true # Note US spelling of color
Add colour to diff
$ git config --global color.diff auto
Configure a visual diff tool
git diff is ok, but not very user friendly.
It represents changes as removal of a line, followed by the addition of a new line.
There are many diff GUIs available, which can be much easier to work with.
To view differences with a GUI instead of using the command-line diff tool, first configure
git to use your chosen diff tool:
$ git config --global diff.tool diffmerge # Set diffmerge as your visual diff tool
$ git config --global difftool.prompt false # Suppress confirmation before launching GUI
Then to use the GUI, use the following command instead of git diff:
$ git difftool
git stash
Sometimes you are working on one branch and want to switch to another branch for
a while.
In order to do so you would normally need to have a clean working directory i.e.
no modified files or staged changes.
You could commit all the changes you have made, then switch branch, but that would
involve committing incomplete work just to return to this state later on.
git stash saves the dirty state of your working directory and saves it on a stack
of unfinished changes that you can reapply at any time using git stash apply.
See here for more details and
for examples.
Password manager/ssh-agent
You can have the ssh-agent manage your password for you so you don’t have to keep entering it.
Start the ssh-agent
$ eval `ssh-agent`
Add your key(s) to the agent:
$ ssh-add
Git GUIs
There are a number of available GUIs for working with Git. The official Git page contains a comprehensive list.
However, Git for Windows already comes with all the tools you need (Git Bash, Git GUI, Shell integration).
Some IDEs already have integration with version control e.g. MATLAB, R studio.
Git configuration
The global configuration file for git .gitconfig is automatically created by
Git in the home directory. If you set up some basic configuration (in the
first steps of this tutorial), it should look like this.
$ cat ~/.gitconfig
[user]
name = Your Name
email = yourname@yourplace.org
[core]
editor = gedit
You can add more configuration options. For example, instead of typing git
commit -m we can have a shorter version of this command:
$ git config --global alias.cms 'commit -m'
And now our configuration file will have a new section added:
[alias]
cms = commit -m
Next time we can simply type:
$ git cms "Commit message"
Completely removing unwanted files from the repository
As we discussed earlier, there are a number of ways to undo what we did in Git. However, most of the time, we actually want to make some amendments rather than discard everything completely. Also often undoing things means, in fact, creating a new commit (not abandoning them). Since Git is a version control system, everything that we recorded in the past commits will be available in the repository.
For example, if you accidentaly commited a file with sensitive data (passwords)
in your local repository and then pushed it to the remote repository, the file
will be there even if in the next commit-and-push you’ll remove it (git rm).
This article provides
a step-by-step tutorial on how to remove completely files from your repository
(purge the repository) using git filter-branch.
Removing files from the repository may be useful not only when the files
contain sensitive data. Another case may be if you commited a large file in
your local repository. Essentially, by default, there are no limitations on the
size of files you can commit. However, there may be (and quite likely there
will be) limits on the size of the files you can push to remote repositories
(GitHub allows for max 100MB). You may encounter an annoying situation when you
commited a large file locally and then kept on working making local commits but
not pushing. Finally, you decide to push to GitHub (or elsewhere remote) and
you can’t because the file is too big. Using git rm won’t help because you
are pushing since the last pushed commit and that means in between there is
a commit with the large problematic file. To recover from this you will have to
purge your large file from the repo (or switch to a different remote repo
provider that allows for large files).
Again, as always with Git before you execute the above, make sure you know what you’re doing!
Key Points
List files to ignore by committing a
.gitignorefileSelectively stage changes to files using
git add --patchConfigure a visual diff tool and use
git difftoolto view changes
Conclusions and further information
Overview
Teaching: 5 min
Exercises: 0 minQuestions
Where can I find out more?
Objectives
Reflect on how version control would help with the starting scenario
We’ve seen how we can use version control to:
- Keep track of changes like a lab notebook for code and documents.
- Roll back changes to any point in the history of changes to our files - “undo” and “redo” for files.
- Back up our entire history of changes in various locations.
- Work on our files from multiple locations.
- Identify and resolve conflicts when the same file is edited within two repositories without losing any work.
- Collaboratively work on code or documents or any other files.
Now, consider again our initial scenario:
If someone asks you, “Can you process a new data file in exactly the same way as described in your journal paper? Or can I have the code to do it myself?” You can use your version control logs and tags to easily retrieve the exact version of the code that you used.
Version control serves as a log book for your software and documents, ideas you’ve explored, fixes you’ve made, refactorings you’ve done, false paths you’ve explored - what was changed, who by, when and why - with a powerful undo and redo feature!
It also allows you to work with others on a project, whether that be writing code or papers, down to the level of individual files, without the risk of overwriting and losing each others work, and being able to record and understand who changed what, when, and why.
Find out more…
- Download and install Git on your own computer (it’s free!)
- Atlassian Git tutorials — an excellent resource with clear explanations and illustrations
- Learn Git branching — interactive, visual tutorials
- K. Ram (2013) “git can facilitate greater reproducibility and increased transparency in science”, Source Code for Biology and Medicine 2013, 8:7 doi:10.1186/1751-0473-8-7 — survey of the range of ways in which version control can help research.
- Visual Git Reference — pictorial representations of what Git commands do
- Pro Git — the “official” online Git book.
- Version control by example — an acclaimed online book on version control by Eric Sink.
- Git beyond the basics — a nice reference slideshow covering some more advanced topics
- G. Wilson, D. A. Aruliah, C. T. Brown, N. P. Chue Hong, M. Davis, R. T. Guy, S. H. D. Haddock, K. Huff, I. M. Mitchell, M. Plumbley, B. Waugh, E. P. White, P. Wilson (2012) “Best Practices for Scientific Computing”, arXiv:1210.0530 [cs.MS].
Feedback
Please leave some feedback. It’s good to know how things can be improved.
Key Points
Use version control whenever possible