Manipulating, analyzing and exporting data with tidyverse
Last updated on 2026-04-28 | Edit this page
Overview
Questions
- What are dplyr and tidyr?
- How can I select specific rows and/or columns from a dataframe?
- How can I combine multiple commands into a single command?
- How can I create new columns or remove existing columns from a dataframe?
Objectives
- Describe the purpose of the
dplyrandtidyrpackages. - Select certain columns in a data frame with the
dplyrfunctionselect. - Extract certain rows in a data frame according to logical (boolean)
conditions with the
dplyrfunctionfilter. - Link the output of one
dplyrfunction to the input of another function with the ‘pipe’ operator%>%. - Add new columns to a data frame that are functions of existing
columns with
mutate. - Use the split-apply-combine concept for data analysis.
- Use
summarize,group_by, andcountto split a data frame into groups of observations, apply summary statistics for each group, and then combine the results. - Describe the concept of a wide and a long table format and for which purpose those formats are useful.
- Describe what key-value pairs are.
- Reshape a data frame from long to wide format and back with the
pivot_widerandpivot_longercommands from thetidyrpackage. - Export a data frame to a .csv file.
Data manipulation using dplyr and
tidyr
Bracket subsetting is handy, but it can be cumbersome and difficult
to read, especially for complicated operations. Enter
dplyr. dplyr
is a package for helping with tabular data manipulation. It pairs nicely
with tidyr which enables you to swiftly
convert between different data formats for plotting and analysis.
The tidyverse package is an
“umbrella-package” that installs tidyr,
dplyr, and several other useful packages
for data analysis, such as ggplot2,
tibble, etc.
The tidyverse package tries to address
3 common issues that arise when doing data analysis in R:
- The results from a base R function sometimes depend on the type of data.
- R expressions are used in a non standard way, which can be confusing for new learners.
- The existence of hidden arguments having default operations that new learners are not aware of.
You should already have installed and loaded the
tidyverse package. If you haven’t already
done so, you can type install.packages("tidyverse")
straight into the console. Then, type library(tidyverse) to
load the package.
What are dplyr and
tidyr?
The package dplyr provides helper tools
for the most common data manipulation tasks. It is built to work
directly with data frames, with many common tasks optimized by being
written in a compiled language (C++). An additional feature is the
ability to work directly with data stored in an external database. The
benefits of doing this are that the data can be managed natively in a
relational database, queries can be conducted on that database, and only
the results of the query are returned.
This addresses a common problem with R in that all operations are conducted in-memory and thus the amount of data you can work with is limited by available memory. The database connections essentially remove that limitation in that you can connect to a database of many hundreds of GB, conduct queries on it directly, and pull back into R only what you need for analysis.
The package tidyr addresses the common
problem of wanting to reshape your data for plotting and usage by
different R functions. For example, sometimes we want data sets where we
have one row per measurement. Other times we want a data frame where
each measurement type has its own column, and rows are instead more
aggregated groups (e.g., a time period, an experimental unit like a plot
or a batch number). Moving back and forth between these formats is
non-trivial, and tidyr gives you tools for
this and more sophisticated data manipulation.
To learn more about dplyr and
tidyr after the workshop, you may want to
check out this handy
data transformation with dplyr
cheatsheet and this one
about tidyr.
As before, we’ll read in our data using the read_csv()
function from the tidyverse package
readr.
R
surveys <- read_csv("data_raw/portal_data_joined.csv")
OUTPUT
#> Rows: 34786 Columns: 13
#> ── Column specification ────────────────────────────────────────────────────────
#> Delimiter: ","
#> chr (6): species_id, sex, genus, species, taxa, plot_type
#> dbl (7): record_id, month, day, year, plot_id, hindfoot_length, weight
#>
#> ℹ Use `spec()` to retrieve the full column specification for this data.
#> ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.R
## inspect the data
str(surveys)
R
## preview the data
view(surveys)
Next, we’re going to learn some of the most common
dplyr functions:
-
select(): subset columns -
filter(): subset rows on conditions -
mutate(): create new columns by using information from other columns -
group_by()andsummarize(): create summary statistics on grouped data -
arrange(): sort results -
count(): count discrete values
Selecting columns and filtering rows
To select columns of a data frame, use select(). The
first argument to this function is the data frame
(surveys), and the subsequent arguments are the columns to
keep.
R
select(surveys, plot_id, species_id, weight)
To select all columns except certain ones, put a “-” in front of the variable to exclude it.
R
select(surveys, -record_id, -species_id)
This will select all the variables in surveys except
record_id and species_id.
To choose rows based on a specific criterion, use
filter():
R
filter(surveys, year == 1995)
Pipes
What if you want to select and filter at the same time? There are three ways to do this: use intermediate steps, nested functions, or pipes.
With intermediate steps, you create a temporary data frame and use that as input to the next function, like this:
R
surveys2 <- filter(surveys, weight < 5)
surveys_sml <- select(surveys2, species_id, sex, weight)
This is readable, but can clutter up your workspace with lots of objects that you have to name individually. With multiple steps, that can be hard to keep track of.
You can also nest functions (i.e. one function inside of another), like this:
R
surveys_sml <- select(filter(surveys, weight < 5), species_id, sex, weight)
This is handy, but can be difficult to read if too many functions are nested, as R evaluates the expression from the inside out (in this case, filtering, then selecting).
The last option, pipes, are a recent addition to R. Pipes
let you take the output of one function and send it directly to the
next, which is useful when you need to do many things to the same
dataset. Pipes in R look like %>% and are made available
via the magrittr package, installed
automatically with dplyr. If you use
RStudio, you can type the pipe with Ctrl
- Shift + M if you have a PC or Cmd + Shift + M if you have a Mac.
R
surveys %>%
filter(weight < 5) %>%
select(species_id, sex, weight)
In the above code, we use the pipe to send the surveys
dataset first through filter() to keep rows where
weight is less than 5, then through select()
to keep only the species_id, sex, and
weight columns. Since %>% takes the object
on its left and passes it as the first argument to the function on its
right, we don’t need to explicitly include the data frame as an argument
to the filter() and select() functions any
more.
Some may find it helpful to read the pipe like the word “then.” For
instance, in the example above, we took the data frame
surveys, then we filtered for rows
with weight < 5, then we selected
columns species_id, sex, and
weight. The dplyr functions
by themselves are somewhat simple, but by combining them into linear
workflows with the pipe we can accomplish more complex manipulations of
data frames.
If we want to create a new object with this smaller version of the data, we can assign it a new name:
R
surveys_sml <- surveys %>%
filter(weight < 5) %>%
select(species_id, sex, weight)
surveys_sml
Note that the final data frame is the leftmost part of this expression.
Challenge
Using pipes, subset the surveys data to include animals
collected before 1995 and retain only the columns year,
sex, and weight.
R
surveys %>%
filter(year < 1995) %>%
select(year, sex, weight)
Mutate
Frequently you’ll want to create new columns based on the values in
existing columns, for example to do unit conversions, or to find the
ratio of values in two columns. For this we’ll use
mutate().
To create a new column of weight in kg:
R
surveys %>%
mutate(weight_kg = weight / 1000)
You can also create a second new column based on the first new column
within the same call of mutate():
R
surveys %>%
mutate(weight_kg = weight / 1000,
weight_lb = weight_kg * 2.2)
If this runs off your screen and you just want to see the first few
rows, you can use a pipe to view the head() of the data.
(Pipes work with non-dplyr functions, too,
as long as the dplyr or
magrittr package is loaded).
R
surveys %>%
mutate(weight_kg = weight / 1000) %>%
head()
The first few rows of the output are full of NAs, so if
we wanted to remove those we could insert a filter() in the
chain:
R
surveys %>%
filter(!is.na(weight)) %>%
mutate(weight_kg = weight / 1000) %>%
head()
is.na() is a function that determines whether something
is an NA. The ! symbol negates the result, so
we’re asking for every row where weight is not an
NA.
Challenge
Create a new data frame from the surveys data that meets
the following criteria: contains only the species_id column
and a new column called hindfoot_cm containing the
hindfoot_length values (currently in mm) converted to
centimeters. In this hindfoot_cm column, there are no
NAs and all values are less than 3.
Hint: think about how the commands should be ordered to produce this data frame!
R
surveys_hindfoot_cm <- surveys %>%
filter(!is.na(hindfoot_length)) %>%
mutate(hindfoot_cm = hindfoot_length / 10) %>%
filter(hindfoot_cm < 3) %>%
select(species_id, hindfoot_cm)
Split-apply-combine data analysis and the summarize()
function
Many data analysis tasks can be approached using the
split-apply-combine paradigm: split the data into groups, apply
some analysis to each group, and then combine the results. Key functions
of dplyr for this workflow are
group_by() and summarize().
The group_by() and summarize()
functions
group_by() is often used together with
summarize(), which collapses each group into a single-row
summary of that group. group_by() takes as arguments the
column names that contain the categorical variables for
which you want to calculate the summary statistics. So to compute the
mean weight by sex:
R
surveys %>%
group_by(sex) %>%
summarize(mean_weight = mean(weight, na.rm = TRUE))
You may also have noticed that the output from these calls doesn’t
run off the screen anymore. It’s one of the advantages of
tbl_df over data frame.
You can also group by multiple columns:
R
surveys %>%
group_by(sex, species_id) %>%
summarize(mean_weight = mean(weight, na.rm = TRUE)) %>%
tail()
OUTPUT
#> `summarise()` has grouped output by 'sex'. You can override using the `.groups`
#> argument.Here, we used tail() to look at the last six rows of our
summary. Before, we had used head() to look at the first
six rows. We can see that the sex column contains
NA values because some animals had escaped before their sex
and body weights could be determined. The resulting
mean_weight column does not contain NA but
NaN (which refers to “Not a Number”) because
mean() was called on a vector of NA values
while at the same time setting na.rm = TRUE. To avoid this,
we can remove the missing values for weight before we attempt to
calculate the summary statistics on weight. Because the missing values
are removed first, we can omit na.rm = TRUE when computing
the mean:
R
surveys %>%
filter(!is.na(weight)) %>%
group_by(sex, species_id) %>%
summarize(mean_weight = mean(weight))
OUTPUT
#> `summarise()` has grouped output by 'sex'. You can override using the `.groups`
#> argument.Here, again, the output from these calls doesn’t run off the screen
anymore. If you want to display more data, you can use the
print() function at the end of your chain with the argument
n specifying the number of rows to display:
R
surveys %>%
filter(!is.na(weight)) %>%
group_by(sex, species_id) %>%
summarize(mean_weight = mean(weight)) %>%
print(n = 15)
OUTPUT
#> `summarise()` has grouped output by 'sex'. You can override using the `.groups`
#> argument.Once the data are grouped, you can also summarize multiple variables at the same time (and not necessarily on the same variable). For instance, we could add a column indicating the minimum weight for each species for each sex:
R
surveys %>%
filter(!is.na(weight)) %>%
group_by(sex, species_id) %>%
summarize(mean_weight = mean(weight),
min_weight = min(weight))
OUTPUT
#> `summarise()` has grouped output by 'sex'. You can override using the `.groups`
#> argument.It is sometimes useful to rearrange the result of a query to inspect
the values. For instance, we can sort on min_weight to put
the lighter species first:
R
surveys %>%
filter(!is.na(weight)) %>%
group_by(sex, species_id) %>%
summarize(mean_weight = mean(weight),
min_weight = min(weight)) %>%
arrange(min_weight)
OUTPUT
#> `summarise()` has grouped output by 'sex'. You can override using the `.groups`
#> argument.To sort in descending order, we need to add the desc()
function. If we want to sort the results by decreasing order of mean
weight:
R
surveys %>%
filter(!is.na(weight)) %>%
group_by(sex, species_id) %>%
summarize(mean_weight = mean(weight),
min_weight = min(weight)) %>%
arrange(desc(mean_weight))
OUTPUT
#> `summarise()` has grouped output by 'sex'. You can override using the `.groups`
#> argument.Counting
When working with data, we often want to know the number of
observations found for each factor or combination of factors. For this
task, dplyr provides count().
For example, if we wanted to count the number of rows of data for each
sex, we would do:
R
surveys %>%
count(sex)
The count() function is shorthand for something we’ve
already seen: grouping by a variable, and summarizing it by counting the
number of observations in that group. In other words,
surveys %>% count() is equivalent to:
R
surveys %>%
group_by(sex) %>%
summarize(count = n())
For convenience, count() provides the sort
argument:
R
surveys %>%
count(sex, sort = TRUE)
Previous example shows the use of count() to count the
number of rows/observations for one factor (i.e.,
sex). If we wanted to count combination of
factors, such as sex and species, we
would specify the first and the second factor as the arguments of
count():
R
surveys %>%
count(sex, species)
With the above code, we can proceed with arrange() to
sort the table according to a number of criteria so that we have a
better comparison. For instance, we might want to arrange the table
above in (i) an alphabetical order of the levels of the species and (ii)
in descending order of the count:
R
surveys %>%
count(sex, species) %>%
arrange(species, desc(n))
From the table above, we may learn that, for instance, there are 75
observations of the albigula species that are not specified for
its sex (i.e. NA).
Challenge
- How many animals were caught in each
plot_typesurveyed?
R
surveys %>%
count(plot_type)
Challenge (continued)
- Use
group_by()andsummarize()to find the mean, min, and max hindfoot length for each species (usingspecies_id). Also add the number of observations (hint: see?n).
R
surveys %>%
filter(!is.na(hindfoot_length)) %>%
group_by(species_id) %>%
summarize(
mean_hindfoot_length = mean(hindfoot_length),
min_hindfoot_length = min(hindfoot_length),
max_hindfoot_length = max(hindfoot_length),
n = n()
)
Challenge (continued)
- What was the heaviest animal measured in each year? Return the
columns
year,genus,species_id, andweight.
R
surveys %>%
filter(!is.na(weight)) %>%
group_by(year) %>%
filter(weight == max(weight)) %>%
select(year, genus, species, weight) %>%
arrange(year)
Reshaping with pivot_longer and pivot_wider
In the spreadsheet lesson, we discussed how to structure our data leading to the four rules defining a tidy dataset:
- Each variable has its own column
- Each observation has its own row
- Each value must have its own cell
- Each type of observational unit forms a table
Here we examine the fourth rule: Each type of observational unit forms a table.
In surveys, the rows of surveys contain the
values of variables associated with each record (the unit), values such
as the weight or sex of each animal associated with each record. What if
instead of comparing records, we wanted to compare the different mean
weight of each genus between plots? (Ignoring plot_type for
simplicity).
We’d need to create a new table where each row (the unit) is
comprised of values of variables associated with each plot. In practical
terms this means the values in genus would become the names
of column variables and the cells would contain the values of the mean
weight observed on each plot.
Having created a new table, it is therefore straightforward to explore the relationship between the weight of different genera within, and between, the plots. The key point here is that we are still following a tidy data structure, but we have reshaped the data according to the observations of interest: average genus weight per plot instead of recordings per date.
The opposite transformation would be to transform column names into values of a variable.
We can do both these of transformations with two tidyr
functions, pivot_wider() and
pivot_longer().
These may sound like dramatically different data layouts, but there are some tools that make transitions between these layouts more straightforward than you might think! The gif below shows how these two formats relate to each other, and gives you an idea of how we can use R to shift from one format to the other.
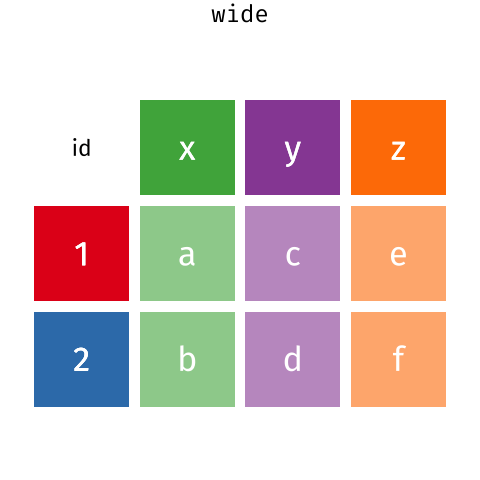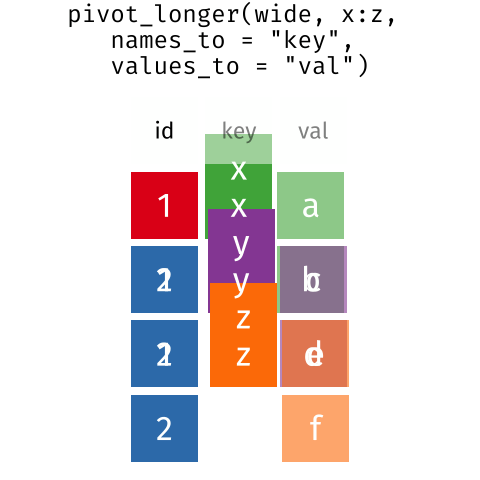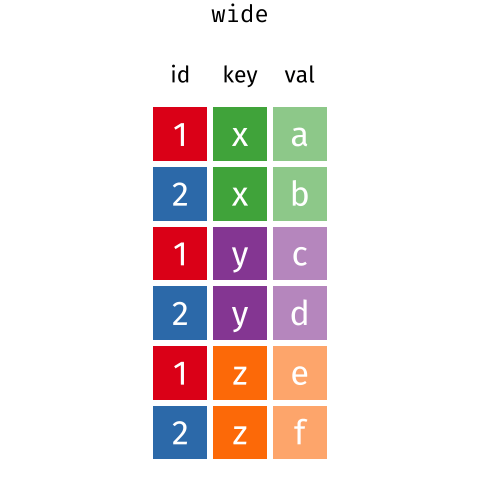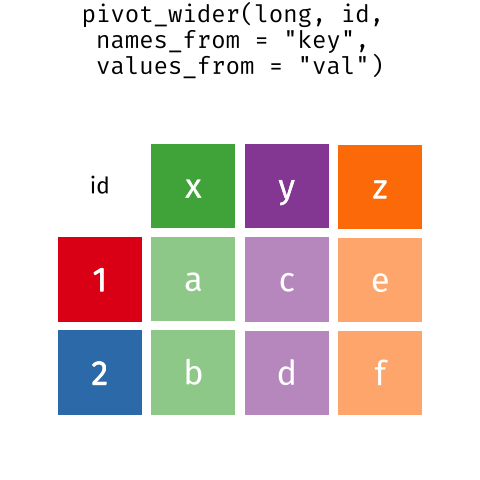
Pivoting from long to wide format
pivot_wider() takes three principal arguments:
- the data
- the names_from column variable whose values will become new column names.
- the values_from column variable whose values will fill the new column variables.
Further arguments include values_fill which, if set,
fills in missing values with the value provided.
Let’s use pivot_wider() to transform surveys to find the
mean weight of each genus in each plot over the entire survey period. We
use filter(), group_by() and
summarize() to filter our observations and variables of
interest, and create a new variable for the
mean_weight.
R
surveys_gw <- surveys %>%
filter(!is.na(weight)) %>%
group_by(plot_id, genus) %>%
summarize(mean_weight = mean(weight))
OUTPUT
#> `summarise()` has grouped output by 'plot_id'. You can override using the
#> `.groups` argument.R
str(surveys_gw)
This yields surveys_gw where the observations for each
plot are distributed across multiple rows, 196 observations of 3
variables. Using pivot_wider() with the names from
genus and with values from mean_weight this
becomes 24 observations of 11 variables, one row for each plot.
R
surveys_wide <- surveys_gw %>%
pivot_wider(names_from = genus, values_from = mean_weight)
str(surveys_wide)

We could now plot comparisons between the weight of genera (one is called a genus, multiple are called genera) in different plots, although we may wish to fill in the missing values first.
R
surveys_gw %>%
pivot_wider(names_from = genus, values_from = mean_weight, values_fill = 0) %>%
head()
Pivoting from wide to long format
The opposing situation could occur if we had been provided with data
in the form of surveys_wide, where the genus names are
column names, but we wish to treat them as values of a genus variable
instead.
In this situation we are reshaping the column names and turning them into a pair of new variables. One variable represents the column names as values, and the other variable contains the values previously associated with the column names.
pivot_longer() takes four principal arguments:
- the data
- the names_to column variable we wish to create from column names.
- the values_to column variable we wish to create and fill with values.
- cols are the name of the columns we use to make this pivot (or to drop).
To recreate surveys_gw from surveys_wide we
would create a names variable called genus and value
variable called mean_weight.
In pivoting longer, we also need to specify what columns to reshape.
If the columns are directly adjacent as they are here, we don’t even
need to list the all out: we can just use the :
operator!
R
surveys_long <- surveys_wide %>%
pivot_longer(names_to = "genus", values_to = "mean_weight", cols = -plot_id)
str(surveys_long)

Note that now the NA genera are included in the long
format data frame. Pivoting wider and then longer can be a useful way to
balance out a dataset so that every replicate has the same
composition
We could also have used a specification for what columns to exclude.
In this example, we will use all columns except
plot_id for the names variable. By using the minus sign in
the cols argument, we omit plot_id from being
reshaped
R
surveys_wide %>%
pivot_longer(names_to = "genus", values_to = "mean_weight", cols = -plot_id) %>%
head()
Challenge
- Reshape the
surveysdata frame withyearas columns,plot_idas rows, and the number of genera per plot as the values. You will need to summarize before reshaping, and use the functionn_distinct()to get the number of unique genera within a particular chunk of data. It’s a powerful function! See?n_distinctfor more.
R
surveys_wide_genera <- surveys %>%
group_by(plot_id, year) %>%
summarize(n_genera = n_distinct(genus)) %>%
pivot_wider(names_from = year, values_from = n_genera)
OUTPUT
#> `summarise()` has grouped output by 'plot_id'. You can override using the
#> `.groups` argument.R
head(surveys_wide_genera)
Challenge (continued)
- Now take that data frame and
pivot_longer()it, so each row is a uniqueplot_idbyyearcombination.
R
surveys_wide_genera %>%
pivot_longer(names_to = "year", values_to = "n_genera", cols = -plot_id)
Challenge (continued)
- The
surveysdata set has two measurement columns:hindfoot_lengthandweight. This makes it difficult to do things like look at the relationship between mean values of each measurement per year in different plot types. Let’s walk through a common solution for this type of problem. First, usepivot_longer()to create a dataset where we have a names column calledmeasurementand avaluecolumn that takes on the value of eitherhindfoot_lengthorweight. Hint: You’ll need to specify which columns will be part of the reshape.
R
surveys_long <- surveys %>%
pivot_longer(names_to = "measurement", values_to = "value", cols = c(hindfoot_length, weight))
- With this new data set, calculate the average of each
measurementin eachyearfor each differentplot_type. Thenpivot_wider()them into a data set with a column forhindfoot_lengthandweight. Hint: You only need to specify the names and values columns forpivot_wider().
R
surveys_long %>%
group_by(year, measurement, plot_type) %>%
summarize(mean_value = mean(value, na.rm=TRUE)) %>%
pivot_wider(names_from = measurement, values_from = mean_value)
OUTPUT
#> `summarise()` has grouped output by 'year', 'measurement'. You can override
#> using the `.groups` argument.Exporting data
Now that you have learned how to use
dplyr to extract information from or
summarize your raw data, you may want to export these new data sets to
share them with your collaborators or for archival.
Similar to the read_csv() function used for reading CSV
files into R, there is a write_csv() function that
generates CSV files from data frames.
Before using write_csv(), we are going to create a new
folder, data, in our working directory that will store this
generated dataset. We don’t want to write generated datasets in the same
directory as our raw data. It’s good practice to keep them separate. The
data_raw folder should only contain the raw, unaltered
data, and should be left alone to make sure we don’t delete or modify
it. In contrast, our script will generate the contents of the
data directory, so even if the files it contains are
deleted, we can always re-generate them.
In preparation for our next lesson on plotting, we are going to prepare a cleaned up version of the data set that doesn’t include any missing data.
Let’s start by removing observations of animals for which
weight and hindfoot_length are missing, or the
sex has not been determined:
R
surveys_complete <- surveys %>%
filter(!is.na(weight), # remove missing weight
!is.na(hindfoot_length), # remove missing hindfoot_length
!is.na(sex)) # remove missing sex
Because we are interested in plotting how species abundances have changed through time, we are also going to remove observations for rare species (i.e., that have been observed less than 50 times). We will do this in two steps: first we are going to create a data set that counts how often each species has been observed, and filter out the rare species; then, we will extract only the observations for these more common species:
R
## Extract the most common species_id
species_counts <- surveys_complete %>%
count(species_id) %>%
filter(n >= 50)
## Only keep the most common species
surveys_complete <- surveys_complete %>%
filter(species_id %in% species_counts$species_id)
To make sure that everyone has the same data set, check that
surveys_complete has 30463 rows and 13 columns by typing
dim(surveys_complete).
Now that our data set is ready, we can save it as a CSV file in our
data folder.
R
write_csv(surveys_complete, file = "data/surveys_complete.csv")
- Use the
dplyrpackage to manipulate data frames. - Use
select()to choose variables from a data frame. - Use
filter()to choose data based on values. - Use
mutate()to create new variables. - Use
group_by()andsummarize()to work with subsets of data.