CMORization: adding new datasets to ESMValTool
Last updated on 2024-11-26 | Edit this page
Overview
Questions
- CMORization: what is it and why do we need it?
- How to use the existing CMORizer scripts shipped with ESMValTool?
- How to add support for new (observational) datasets?
Objectives
- Understand what CMORization is and why it is necessary.
- Use existing scripts to CMORize your data.
- Write a new CMORizer script to support additional data.
Introduction
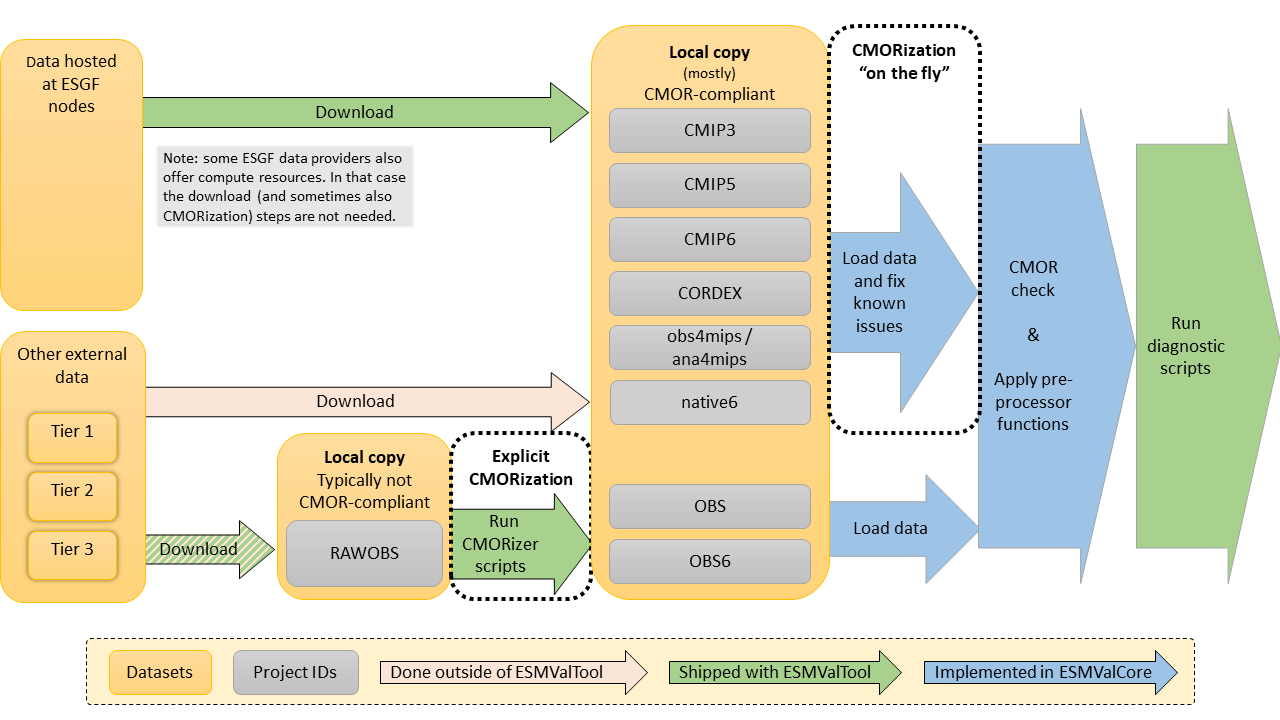
This episode deals with “CMORization”. ESMValTool is designed to work with data that follow the CMOR standards. Unfortunately, not all datasets follow these standards. In order to use such datasets in ESMValTool we first need to reformat the data. This process is called “CMORization”.
What are the CMOR standards?
The name “CMOR” originates from a tool: the Climate Model Output Rewriter. This tool is used to create “CF-Compliant netCDF files for use in the CMIP projects”. So CMOR extends the CF-standard with additional requirements for the Coupled Model Intercomparison Projects (see e.g. here).
Concretely, the CMOR standards dictate e.g. the variable names and units, coordinate information, how the data should be structured (e.g. 1 variable per file), additional metadata requirements, and file naming conventions a.k.a. the data reference syntax (DRS). All this information is stored in so-called CMOR tables. For example, the CMOR tables for the CMIP6 project can be found here.
ESMValTool offers two ways to CMORize data:
- A reformatting script can be used to create a CMOR-compliant copy. CMORizer scripts for several popular datasets are included in ESMValTool, and ESMValTool also provides a convenient way to execute them.
- ESMValCore can execute CMOR fixes ‘[on the fly](https://docs.esmvaltool.org/projects/esmvalcore/en/latest/develop/ fixing_data.html#fixing-data)’. The advantage is that you don’t need to store an additional, reformatted copy of the data. The disadvantage is that these fixes should be implemented inside ESMValCore, which is beyond the scope of this tutorial.
In this lesson, we will re-implement a CMORizer script for the FLUXCOM dataset that contains observations of the Gross Primary Production (GPP), a variable that is important for calculating components of the global carbon cycle. See the next section on how to obtain data.
As in the previous episode (Development and Contribution episode ), we will be using the development installation of ESMValTool.
Obtaining the data
The data for this episode is available via the FluxCom Data
Portal. First you’ll need to register. After registration, in the
dropdown boxes, select FLUXCOM as the data choice and click download.
Three files will be displayed. Click the download button on the “FLUXCOM
(RS+METEO) Global Land Carbon Fluxes using CRUNCEP climate data”. You’ll
receive an email with the FTP address to access the server. Connect to
the server, follow the path in your email, and look for the file
raw/monthly/GPP.ANN.CRUNCEPv6.monthly.2000.nc. Download
that file and save it in a folder called
~/data/RAWOBS/Tier3/FLUXCOM.
Note: you’ll need a user-friendly ftp client. On Linux,
ncftp works okay.
What is the deal with those “tiers”?
Many datasets come with access restrictions. In this way the data providers can keep track of how their data is used. In many cases “restricted access” just means that one has to register with an email address and accept the terms of use, which typically ask that you acknowledge the data providers.
There are also datasets available that do not need a registration. The “obs4MIPs” or “ana4MIPs” datasets, for example, are specifically produced to facilitate comparisons with model simulations.
To reflect these different levels of access restriction, the ESMValTool team has created a tier-system. The definition of the different tiers are as follows:
- Tier1: obs4MIPs and ana4MIPS datasets (can be used directly with the ESMValTool)
- Tier2: other freely available datasets (most of them will need some kind of cmorization)
- Tier3: datasets with access restrictions (most of these datasets will also need some kind of cmorization)
These access restrictions are also why the ESMValTool developers cannot distribute copies or automate downloading of all observations and reanalysis data used in the recipes. As a compromise, we provide the CMORization scripts so that each user can CMORize their own copy of the access restricted datasets if needed.
Run the existing CMORizer script
Before we develop our own CMORizer script, let’s first see what happens when we run the existing one. There is a specific command available in the ESMValTool to run the CMORizer scripts:
The config-user.yml is the file in which we define the
different data paths, see the episode on Configuration. In the
rootpath of your config-user.yml, make sure to
add the right directory for “RAWOBS” data in which you downloaded the
FLUXCOM dataset:
This enables ESMValTool to find the raw observational datasets stored
in the “RAWOBS” folder. The dataset-name needs to be
identical to the folder name that was created to store the raw
observation data files, i.e. RAWOBS/TierX/dataset-name. In
our case this would be “FLUXCOM”.
If everything is okay, the output should look something like this:
OUTPUT
...
... Starting the CMORization Tool at time: 2022-07-26 14:02:16 UTC
... ----------------------------------------------------------------------
... input_dir = /home/peter/data/RAWOBS
... output_dir = /home/peter/esmvaltool_output/data_formatting_20220726_140216
... ----------------------------------------------------------------------
... Running the CMORization scripts.
... Processing datasets ['FLUXCOM']
... Input data from: /home/peter/data/RAWOBS/Tier3/FLUXCOM
... Output will be written to: /home/peter/esmvaltool_output/
data_formatting_20220726_140216/Tier3/FLUXCOM
... Reformat script: /home/peter/mambaforge/envs/esmvaltool/lib/python3.9/
site-packages/esmvaltool/cmorizers/data/formatters/datasets/fluxcom
... CMORizing dataset FLUXCOM using Python script /home/peter/mambaforge/envs/
esmvaltool/lib/python3.9/site-packages/esmvaltool/cmorizers/data/formatters/
datasets/fluxcom.py
... Found input file '/home/peter/data/RAWOBS/Tier3/FLUXCOM/GPP.ANN.CRUNCEPv6.monthly.*.nc'
... CMORizing variable 'gpp'
... Lmon
... Var is gpp
... ... UserWarning: Ignoring netCDF variable 'GPP' invalid units 'gC m-2 day-1'
... Fixing time...
... Fixing latitude...
... Fixing longitude...
... Flipping dimensional coordinate latitude...
... Saving file
... Saving: /home/peter/esmvaltool_output/data_formatting_20220726_140216/Tier3/
FLUXCOM/OBS_FLUXCOM_reanaly_ANN-v1_Lmon_gpp_200001-200012.nc
... Cube has lazy data [lazy is preferred]
... CMORization of dataset FLUXCOM finished!
... Formatting successful for dataset FLUXCOMSo you can see that several fixes are applied, and the CMORized file
is written to the ESMValTool output directory, i.e.
~/esmvaltool_output/data_formatting_YYYYMMDD_HHMMSS/TierX/dataset-name/filename.nc
In order to use it, we’ll have to copy it from the output directory to a
folder called ~/data/OBS/Tier3/FLUXCOM and make sure the
path to OBS is set correctly in our config-user file:
You can also see the path where ESMValTool stores the reformatting
script:
~/ESMValTool/esmvaltool/data/formatters/datasets/fluxcom.py.
You may have a look at this file if you want. The script also uses a
configuration file:
~/ESMValTool/esmvaltool/cmorizers/data/cmor_config/FLUXCOM.yml.
Make a test recipe
To verify that the data is correctly CMORized, we will make a simple test recipe. As illustrated in the figure at the top of this episode, one of the steps that ESMValTool executes is a CMOR-check. If the data is not correctly CMORized, ESMValTool will give a warning or error.
Create a test recipe
Create a simple recipe called recipe_check_fluxcom.yml that
loads the FLUXCOM data. It should include a datasets section with a
single entry for the “FLUXCOM” dataset with the correct dataset keys,
and a diagnostics section with two variables: gpp. We don’t need any
preprocessors or scripts (set scripts: null), but we have
to add a documentation section with a description, authors and
maintainer, otherwise the recipe will fail.
Use the following dataset keys:
- project: OBS
- dataset: FLUXCOM
- type: reanaly
- version: ANN-v1
- mip: Lmon
- start_year: 2000
- end_year: 2000
- tier: 3
Some of these dataset keys are further explained in the callout boxes in this episode.
Here’s an example recipe
YAML
documentation:
description: Test recipe for FLUXCOM data
title: This is a test recipe for the FLUXCOM data.
authors:
- kalverla_peter
maintainer:
- kalverla_peter
datasets:
- {project: OBS, dataset: FLUXCOM, mip: Lmon, tier: 3, start_year: 2000,
end_year: 2000, type: reanaly, version: ANN-v1}
diagnostics:
check_fluxcom:
description: Check that ESMValTool can load the cmorized fluxnet data without errors.
variables:
gpp:
scripts: nullTo learn more about writing a recipe, please refer to Writing your own recipe.
Try to run the example recipe with
BASH
esmvaltool run recipe_check_fluxcom.yml --config_file <path to config-user.yml> --log_level debugIf everything is okay, the recipe should run without problems.
Starting from scratch
Now that you’ve seen how to use an existing CMORizer script, let’s think about adding a new one. We will remove the existing CMORizer script, and re-implement it from scratch. This exercise allows us to point out all the details of what’s going on. We’ll also remove the CMORized data that we’ve just created, so our test recipe will not be able to use it anymore.
BASH
rm ~/data/OBS/Tier3/FLUXCOM/OBS_FLUXCOM_reanaly_ANN-v1_Lmon_gpp_200001-200012.nc
rm ~/ESMValTool/esmvaltool/cmorizers/data/formatters/datasets/fluxcom.py
rm ~/ESMValTool/esmvaltool/cmorizers/data/cmor_config/FLUXCOM.ymlIf you now run the test recipe again it should fail, and somewhere in the output you should find something like:
ERROR
No input files found for ...
Looked for files matching: /home/peter/data/OBS/Tier3/
FLUXCOM/OBS_FLUXCOM_reanaly_ANN-v1_Lmon_gpp[_.]*ncFrom this we can see that the first thing our CMORizer should do is to rename the file so that it follows the CMOR filename conventions.
Create a new CMORizer script and a corresponding config file
The first step now is to create a new file in the right folder that
will contain our new CMORizer instructions. Create a file called
fluxcom.py
and fill it with the following boilerplate code:
PYTHON
"""ESMValTool CMORizer for FLUXCOM GPP data.
<We will add some useful info here later>
"""
import logging
from esmvaltool.cmorizers.data import utilities as utils
logger = logging.getLogger(__name__)
def cmorization(in_dir, out_dir, cfg, cfg_user, start_date, end_date):
"""Cmorize the dataset."""
# This is where you'll add the cmorization code
# 1. find the input data
# 2. apply the necessary fixes
# 3. store the data with the correct filenameHere, in_dir corresponds to the input directory of the
raw files, out_dir to the output directory of final
reformatted data set and cfg to a configuration dictionary
given by a configuration file that we will get to shortly. The last
three arguments will not be considered in this script but can be used in
other cases. cfg_user corresponds to the user configuration
file, start_date to the start of the period to format, and
end_date to the end of the period to format. When you type
the command esmvaltool data format in the terminal,
ESMValTool will call this function with the settings found in your
configuration files.
The ESMValTool CMORizer also needs a dataset configuration file.
Create a file called
~/ESMValTool/esmvaltool/cmorizers/data/cmor_config/FLUXCOM.yml
and fill it with the following boilerplate:
YAML
---
# filename: ???
attributes:
project_id: OBS6
# dataset_id: ???
# version: ???
# tier: ???
# modeling_realm: ???
# source: ???
# reference: ???
# comment: ???
# variables:
# ???:
# mip: ???Note: the name of this file must be
identical to dataset-name.
As you can see, the configuration file contains information about the original filename of the dataset, and some additional metadata that you might recognize from the CMOR filename structure. It also contains a list of variables that’s available for this dataset. We’ll add this information step by step in the following sections.
RAWOBS, OBS, OBS6!?
In the configuration above we’ve already filled in the
project_id. ESMValTool uses these project IDs to find the
data on your hard drive, and also to find more information about the
data. The RAWOBS and OBS projects refer to
external data before and after CMORization, respectively.
Historically, most external data were observations, hence the
naming.
In going from CMIP5 to CMIP6, the CMOR standards changed a bit. For
example, some variables were renamed, which posed a dilemma: should
CMORization reformat to the CMIP5 or CMIP6 definition? To solve this,
the OBS6 project was created. So OBS6 data
follow the CMIP6 standards, and that’s what we’ll use for the new
CMORizer.
You can try running the CMORizer at this point, and it should work without errors. However, it doesn’t produce any output yet:
1. Find the input data
First we’ll get the CMORizer script to locate our FLUXCOM data. We
can use the information from the in_dir and
cfg variables. Add the following snippet to your CMORizer
script:
If you run the CMORizer again, it will print out the content of these variables and the output should contain something like this:
OUTPUT
... in_dir: '/home/peter/data/RAWOBS/Tier3/FLUXCOM'
... cfg: '{'attributes': {'project_id': 'OBS6', 'comment': ''},
'cmor_table': <esmvalcore.cmor.table.CMIP6Info object at 0x7fbd0a0f6bf0>}'Load the data
Try to locate the input data inside the CMORizer script and load it
(we’ll use iris because ESMValTool includes helper
utilities for iris cubes). Confirm that you’ve loaded the data by
logging the correct path and (part of the) file content.
There are many ways to do it. In any case, you should have added the
original filename to the configuration file (and un-commented this
line): filename: 'GPP.ANN.CRUNCEPv6.monthly.*.nc'. Note the
*: this is a useful shorthand to find multiple files for
different years. In a similar way we can also look for multiple
variables, etc.
Here’s an example solution (inserted directly under the original comment):
PYTHON
# 1. find the input data
filename_pattern = cfg['filename']
matches = Path(in_dir).glob(filename_pattern)
for match in matches:
input_file = str(match)
logger.info("found: %s", input_file)
cube = iris.load_cube(input_file)
logger.info("content: %s", cube)To make this work we’ve added import iris and
from pathlib import Path at the top of the file. Note that
we’ve started a loop, since we may find multiple files if there’s more
than one year of data available.
2. Save the data with the correct filename
Before we start adding fixes, we’ll first make sure that our CMORizer can also write output files with the correct name. This will enable us to use the test recipe for the CMOR compatibility check.
We can use the save function from the utils
that we imported at the top. The call signature looks like this:
utils.save_variables(cube, var, outdir, attrs, **kwargs).
We already have the cube and the outdir.
The variable short name (var) and attributes
(attrs) are set through the configuration file. So we need
to find out what the correct short name and attributes are.
The standard attributes for CMIP variables are defined in the CMIP tables. These tables are differentiated according to the “MIP” they belong to. The tables are a copy of the PCMDI guidelines.
Find the variable “gpp” in a CMOR table
Check the available CMOR tables to find the variable “gpp” with the following characteristics:
- standard_name:
gross_primary_productivity_of_biomass_expressed_as_carbon - frequency:
mon - modeling_realm:
land
The variable “gpp” belongs to the land variables. The temporal resolution that we are looking for is “monthly”. This information points to the “Lmon” CMIP table. And indeed, the variable “gpp” can be found in the file [here](https://github.com/ESMValGroup/ESMValCore/blob/main/esmvalcore/ cmor/tables/cmip6/Tables/CMIP6_Lmon.json).
If the variable you are interested in is not available in the standard CMOR tables, you could write a custom CMOR table entry for the variable. This, however, is beyond the scope of this tutorial.
Fill the configuration file
Uncomment the following entries in your configuration file and fill them with appropriate values:
- dataset_id
- version
- tier
- modeling_realm
- short_name (the ??? immediately under
variables) - mip
Now that we have set this information correctly in the config file, we can call the save function. Add the following python code to your CMORizer script:
PYTHON
# 3. store the data with the correct filename
attributes = cfg['attributes']
variables = cfg['variables']
for short_name, variable_info in variables.items():
all_attributes = {**attributes, **variable_info} # add the mip to the other attributes
utils.save_variable(cube=cube, var=short_name, outdir=out_dir, attrs=all_attributes)Since we only have one variable (gpp), the loop is not strictly necessary. However, this makes it possible to add more variables later on.
Was the CMORization successful so far?
If you run the CMORizer again, you should see that it creates an
output file named
OBS6_FLUXCOM_reanaly_ANN-v1_Lmon_gpp_xxxx01-xxxx12.nc
stored in your ESMValTool output directory
~/esmvaltool_output/data_formatting_YYYYMMDD_HHMMSS/Tier3/FLUXCOM/.
The “xxxx” and “yyyy” represent the start and end year of the data.
Great! So we have produced a NetCDF file with the CMORizer that follows the naming convention for ESMValTool datasets. Let’s have a look at the NetCDF file as it was written with the very basic CMORizer from above.
OUTPUT
netcdf OBS6_FLUXCOM_reanaly_ANN-v1_Lmon_gpp_200001-200012 {
dimensions:
time = 12 ;
lat = 360 ;
lon = 720 ;
variables:
float GPP(time, lat, lon) ;
GPP:_FillValue = 1.e+20f ;
GPP:long_name = "GPP" ;
double time(time) ;
time:axis = "T" ;
time:units = "days since 1582-10-15 00:00:00" ;
time:standard_name = "time" ;
time:calendar = "gregorian" ;
double lat(lat) ;
double lon(lon) ;
// global attributes:
:_NCProperties = "version=2,netcdf=4.7.4,hdf5=1.10.6" ;
:created_by = "Fabian Gans [fgans@bgc-jena.mpg.de], Ulrich Weber
[uweber@bgc-jena.mpg.de]" ;
:flux = "GPP" ;
:forcing = "CRUNCEPv6" ;
:institution = "MPI-BGC-BGI" ;
:invalid_units = "gC m-2 day-1" ;
:method = "Artificial Neural Networks" ;
:provided_by = "Martin Jung [mjung@bgc-jena.mpg.de] on behalf of FLUXCOM team" ;
:reference = "Jung et al. 2016, Nature; Tramontana et al. 2016, Biogeosciences" ;
:temporal_resolution = "monthly" ;
:title = "GPP based on FLUXCOM RS+METEO with CRUNCEPv6 climate " ;
:version = "v1" ;
:Conventions = "CF-1.7" ;
}The file contains a variable named “GPP” that contains three
dimensions: “time”, “lat”, “lon”. Notice the strange time units, and the
invalid_units in the global attributes section. Also it
seems that there is not information available about the lat and lon
coordinates. These are just some of the things we’ll address in the next
section.
3. Implementing additional fixes
Copy the output of the CMORizer to your folder
~/data/OBS6/Tier3/FLUXCOM/ and change the test recipe to
look for OBS6 data instead of OBS (note: we’re upgrading the CMORizer to
newer standards here!). Make sure the path to OBS6 is set
correctly in our config-user file:
If we now run the test recipe on our newly ‘CMORized’ data,
BASH
esmvaltool run recipe_check_fluxcom.yml --config_file <path to config-user.yml> --log_level debugit should be able to find the correct file, but it does not succeed yet. The first thing that the ESMValTool CMOR checker brings up is:
ERROR
iris.exceptions.UnitConversionError: Cannot convert from unknown units. The
"units" attribute may be set directly.If you look closely at the error messages, you can see that this error concerns the units of the coordinates. ESMValTool tries to fix them automatically, but since no units are defined on the coordinates, this fails.
The cmorizer utilities also include a function called
fix_coords, but before we can use it, we’ll also need to
make sure the coordinates have the correct standard name. Add the
following code to your cmorizer:
PYTHON
# 2. Apply the necessary fixes
# 2a. Fix/add coordinate information and metadata
cube.coord('lat').standard_name = 'latitude'
cube.coord('lon').standard_name = 'longitude'
utils.fix_coords(cube)With some additional refactoring, our cmorization function might then look something like this:
PYTHON
def cmorization(in_dir, out_dir, cfg, cfg_user, start_date, end_date):
"""Cmorize the dataset."""
# Get general information from the config file
attributes = cfg['attributes']
variables = cfg['variables']
for short_name, variable_info in variables.items():
logger.info("CMORizing variable: %s", short_name)
# 1a. Find the input data (one file for each year)
filename_pattern = cfg['filename']
matches = Path(in_dir).glob(filename_pattern)
for match in matches:
# 1b. Load the input data
input_file = str(match)
logger.info("found: %s", input_file)
cube = iris.load_cube(input_file)
# 2. Apply the necessary fixes
# 2a. Fix/add coordinate information and metadata
cube.coord('lat').standard_name = 'latitude'
cube.coord('lon').standard_name = 'longitude'
utils.fix_coords(cube)
# 3. Save the CMORized data
all_attributes = {**attributes, **variable_info}
utils.save_variable(cube=cube, var=short_name, outdir=out_dir, attrs=all_attributes)Run the CMORizer script once more. Have a look at the netCDF file, and confirm that the coordinates now have much more metadata added to them. Then, run the test recipe again with the latest CMORizer output. The next error is:
ERROR
esmvalcore.cmor.check.CMORCheckError: There were errors in variable GPP:
Variable GPP units unknown can not be converted to kg m-2 s-1 in cube:Okay, so let’s fix the units of the “GPP” variable in the CMORizer. Remember that you can find the correct units in the CMOR table. Add the following three lines to our CMORizer:
PYTHON
# 2b. Fix gpp units
logger.info("Changing units for gpp from gc/m2/day to kg/m2/s")
cube.data = cube.core_data() / (1000 * 86400)
cube.units = 'kg m-2 s-1'If everything is okay, the test recipe should now pass. We’re getting there. Looking through the output though, there’s still a warning.
OUTPUT
WARNING There were warnings in variable GPP:
Standard name for GPP changed from None to gross_primary_productivity_of_biomass_expressed_as_carbon
Long name for GPP changed from GPP to Carbon Mass Flux out of Atmosphere Due to
Gross Primary Production on Land [kgC m-2 s-1]ESMValTool is able to apply automatic fixes here, but if we are running a CMORizer script anyway, we might as well fix it immediately.
Add the following snippet:
PYTHON
# 2c. Fix metadata
cmor_table = cfg['cmor_table']
cmor_info = cmor_table.get_variable(variable_info['mip'], short_name)
utils.fix_var_metadata(cube, cmor_info)You can see that we’re using the CMOR table here. This was passed on
by ESMValTool as part of the CFG input variable. So here
we’re making sure that we’re updating the cubes metadata to conform to
the CMOR table.
Finally, the test recipe should run without errors or warnings.
4. Finalizing the CMORizer
Once everything works as expected, there’s a couple of things that we can still do.
- Add download instructions. The header of the CMORizer contains information about where to obtain the data, when it was accessed the last time, which ESMValTool “tier” it is associated with, and more detailed information about the necessary downloading and processing steps.
Fill out the header for the “FLUXCOM” dataset
Fill out the header of the new CMORizer. The different parts that need to be present in the header are the following:
- Caption: the first line of the docstring should summarize what the script does.
- Tier
- Source
- Last access
- Download and processing instructions
The header for the “FLUXCOM” dataset could look something like this:
PYTHON
"""ESMValTool CMORizer for FLUXCOM GPP data.
Tier
Tier 3: restricted dataset.
Source
http://www.bgc-jena.mpg.de/geodb/BGI/Home
Last access
20190727
Download and processing instructions
From the website, select FLUXCOM as the data choice and click download.
Two files will be displayed. One for Land Carbon Fluxes and one for
Land Energy fluxes. The Land Carbon Flux file (RS + METEO) using
CRUNCEP data file has several data files for different variables.
The data for GPP generated using the
Artificial Neural Network Method will be in files with name:
GPP.ANN.CRUNCEPv6.monthly.\*.nc
A registration is required for downloading the data.
Users in the UK with a CEDA-JASMIN account may request access to the jules
workspace and access the data.
Note : This data may require rechunking of the netcdf files.
This constraint will not exist once iris is updated to
version 2.3.0 Aug 2019
"""- Fill the dataset information list. The file [datasets.yml](https://github.com/ESMValGroup/ESMValTool/blob/main/esmvaltool/ cmorizers/data/datasets.yml) contains the ESMValTool “tier”, the data source, the last access time and download instructions for all supported datasets in ESMValTool. You can simply reuse the information written in the header of the CMORizer.
Fill out the FLUXCOM entry in
datasets.yml
Fill out the FLUXCOM entry in datasets.yml. The
different parts that need to be present in the entry are the
following:
- Dataset-name
- Tier
- Source
- Last access
- Download and processing instructions
The entry for the “FLUXCOM” dataset should look like:
YAML
FLUXCOM:
tier: 3
source: http://www.bgc-jena.mpg.de/geodb/BGI/Home
last_access: 2019-07-27
info: |
From the website, select FLUXCOM as the data choice and click download.
Two files will be displayed. One for Land Carbon Fluxes and one for
Land Energy fluxes. The Land Carbon Flux file (RS + METEO) using
CRUNCEP data file has several data files for different variables.
The data for GPP generated using the
Artificial Neural Network Method will be in files with name:
GPP.ANN.CRUNCEPv6.monthly.*.nc
A registration is required for downloading the data.
Users in the UK with a CEDA-JASMIN account may request access to the jules
workspace and access the data.
Note : This data may require rechunking of the netcdf files.
This constraint will not exist once iris is updated to
version 2.3.0 Aug 2019Once the datasets.yml file is filled, you can check that
ESMValTool can display information about the added dataset with:
If everything is okay, the output should look something like this:
OUTPUT
$ esmvaltool data info FLUXCOM
FLUXCOM
Tier: 3
Source: http://www.bgc-jena.mpg.de/geodb/BGI/Home
Automatic download: No
From the website, select FLUXCOM as the data choice and click download.
Two files will be displayed. One for Land Carbon Fluxes and one for
Land Energy fluxes. The Land Carbon Flux file (RS + METEO) using
CRUNCEP data file has several data files for different variables.
The data for GPP generated using the
Artificial Neural Network Method will be in files with name:
GPP.ANN.CRUNCEPv6.monthly.*.nc
A registration is required for downloading the data.
Users in the UK with a CEDA-JASMIN account may request access to the jules
workspace and access the data.
Note : This data may require rechunking of the netcdf files.
This constraint will not exist once iris is updated to
version 2.3.0 Aug 2019Note that Automatic download: No means that no automatic
downloading script is available in ESMValTool for this dataset. The
implementation of such a script is beyond the scope of this tutorial. To
find out which datasets come with an automatic download script, you can
run: esmvaltool data list to list all datasets supported in
ESMValTool. More information about the usage of automatic downloading
scripts can be found in the User
Guide.
- Complete the metadata in the config file. We have left a few fields empty in the configuration file, such as ‘source’. By filling out these fields we can make sure the relevant metadata is passed on as attributes in the CMORized data. To make this work, add the following line to the CMORizer script:
PYTHON
# 2d. Update the cubes metadata with all info from the config file
utils.set_global_atts(cube, attributes)Add a reference. Make sure that there is a reference file available for the dataset, see the instruction [here](https://docs.esmvaltool.org/en /latest/community/diagnostic.html#adding-references).
Make a pull request. Since you have gone through all the trouble to reformat the dataset so that the ESMValTool can work with it, it would be great if you could provide the CMORizer, and ultimately with that the dataset, to the rest of the community. For more information, see the episode on Development and contribution.
Add documentation. Make sure that you have added the info of your dataset to the User Guide so that people know it is available for the ESMValTool Obtaining input data.
Some final comments
Congratulations! You have just added support for a new dataset to ESMValTool! Adding a new CMORizer is definitely already an advanced task when working with the ESMValTool. You need to have a basic understanding of how the ESMValTool works and how it’s internal structure looks like. In addition, you need to have a basic understanding of NetCDF files and a programming language. In our example we used python for the CMORizing script since we advocate for focusing the code development on only a few different programming languages. This helps to maintain the code and to ensure the compatibility of the code with possible fundamental changes to the structure of the ESMValTool and ESMValCore.
More information about adding observations to the ESMValTool can be found in the documentation.
Key Points
- CMORizers are dataset-specific scripts that can be run once to generate CMOR-compliant data.
- ESMValTool comes with a set of CMORizers readily available, but you can also add your own.